Overview
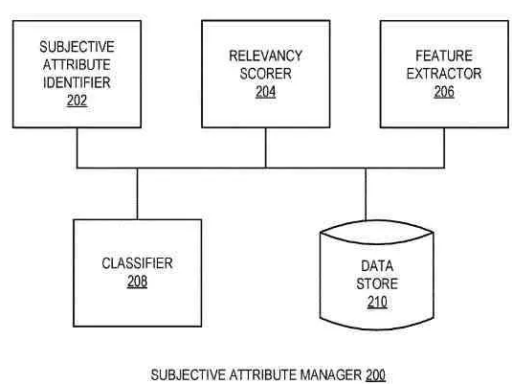
Google developed a sophisticated system for determining which web documents deserve a place in their search index. Rather than blindly cataloging every webpage encountered, the system employs predictive modeling to evaluate a document’s potential utility to search users.
Core Components
The system architecture consists of four primary elements:
- Crawler Engine
- Model Generator Engine
- Indexing Engine
- Database
Document Quality Assessment Framework
Primary Evaluation Metrics
Selection Probability
- Measures likelihood of user clicks when document appears in results
- Accounts for result positioning impact on click probability
- Analyzes historical click patterns
Presentation Probability
- Tracks frequency of document appearances in search results
- Considers impression data from past index inclusions
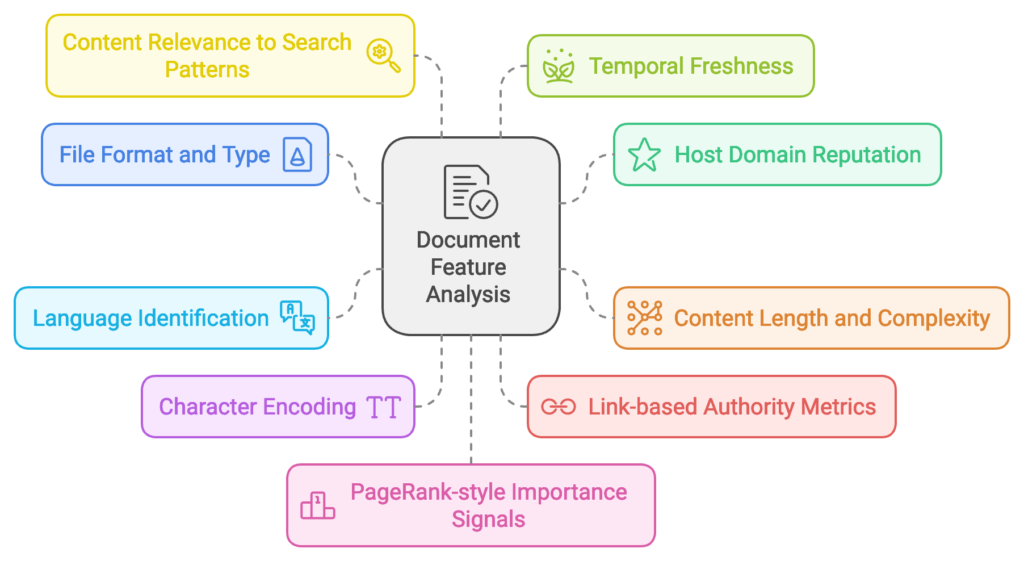
Document Feature Analysis
The system evaluates multiple document characteristics:
- File format and type
- Host domain reputation
- Content length and complexity
- Language identification
- Character encoding
- Link-based authority metrics
- Content relevance to search patterns
- Temporal freshness
- PageRank-style importance signals
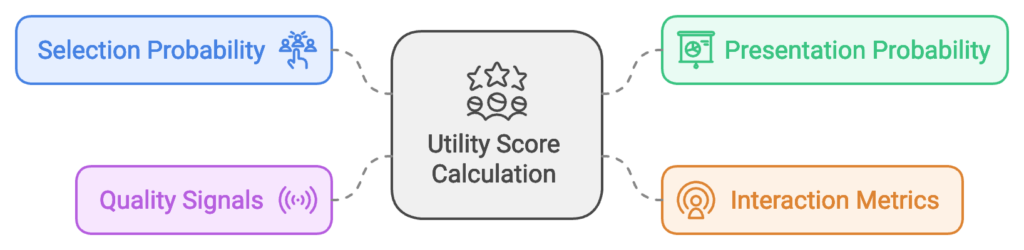
Utility Score Calculation
Core Formula Components
The system generates a utility score through a complex calculation incorporating:
- Daily selection probability (click-through rate)
- Daily presentation probability (impression likelihood)
- Position-adjusted interaction metrics
- Quality signals weighted by importance
Resource Optimization
Cost Considerations
The system balances utility against resource requirements:
- Storage space needed for indexing
- Processing overhead
- Maintenance costs
Indexing Decisions
Final inclusion decisions weigh multiple factors:
- Predicted utility score
- Resource cost assessment
- Content diversity requirements
- Language representation quotas
- Geographic distribution targets
SEO Implications
Key Optimization Areas
- User Engagement Focus
- Click-through rate optimization
- Search result performance
- User satisfaction signals
Technical Excellence
- Proper file formatting
- Clean encoding
- Efficient storage footprint
Content Quality
- Fresh, updated content
- Matching live versions
- Topic relevance
Authority Building
- Link quality
- Domain reputation
- Overall importance metrics
Strategic Considerations
- Performance history influences future indexing
- Space efficiency impacts inclusion probability
- Content diversity quotas create niche opportunities
- Fresh content receives preferential treatment
- Machine learning models evaluate potential value
Patent Claims
The patent outlines specific claims regarding document selection for indexing:
Quality Measure Determination:
Assesses each document’s quality based on probabilities for:
- Being selected as a search result.
- Being presented as a search result.
- Prediction and Storage of Quality Measures: Documents predicted to have high quality are prioritized for indexing, with predictions stored to refine future selection.
- User engagement metrics, including click-through rate and relevance.
- Prioritization for New Documents: New documents undergo a predictive evaluation based on their features, allowing the system to decide their suitability for inclusion in the index.
How Document Quality is Measured
Document quality depends on multiple factors:
- Click Probability: Calculated from past click data, indicating the likelihood of a document being clicked when displayed in search results.
- Impression Probability: How often a document appears in search results when relevant queries are made.
- Position Influence: The rank of a document in search results impacts its click likelihood.
- Document-Specific Features: These include file type, domain, length, language, encoding type, and link-based scores like PageRank.
- Topic Relevance and Freshness: The system considers if a document is relevant to frequently or rarely searched topics and if the indexed version is current.
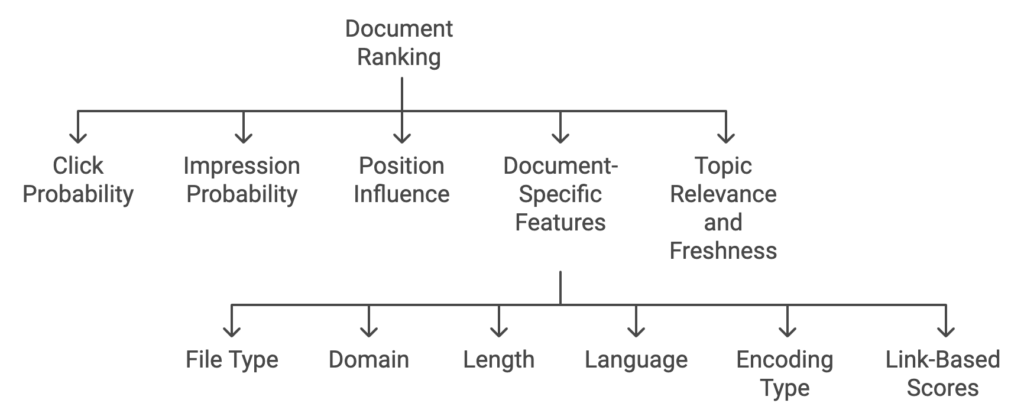
By combining these factors, the system generates a utility score for each document, helping determine which should be included in the index.
Patent Details
- ID: US8554759B1
- Assignee: Google LLC
- Jurisdiction: United States
- Publication: October 8, 2013
- Expiration: January 30, 2028
- Inventors: Sharmila Subramaniam, Thomas M. Annau, Charles Garrett, Sanjay Joshi, Rosemary Emery-Montemerlo, Aaron A. Kools