The patent titled “Classifying Resources Using a Deep Network” revolves around improving how internet search engines categorize online resources such as web pages, images, text documents, or multimedia content.
- These resources are categorized to provide users with the most relevant and valuable information based on their search queries.
- Search engines are designed to deliver a set of search results that best match the user’s needs.
- This patent aims to enhance this matching process through a deep network capable of classifying resources more effectively.
- The core innovation is the use of a deep learning network is to classify resources into pre-defined categories.
This technology can categorize content more accurately, distinguishing between spam and legitimate resources or between different types of resources, which enhances search engine results.
Key Components of the Patent
Input Features and Embedding Functions
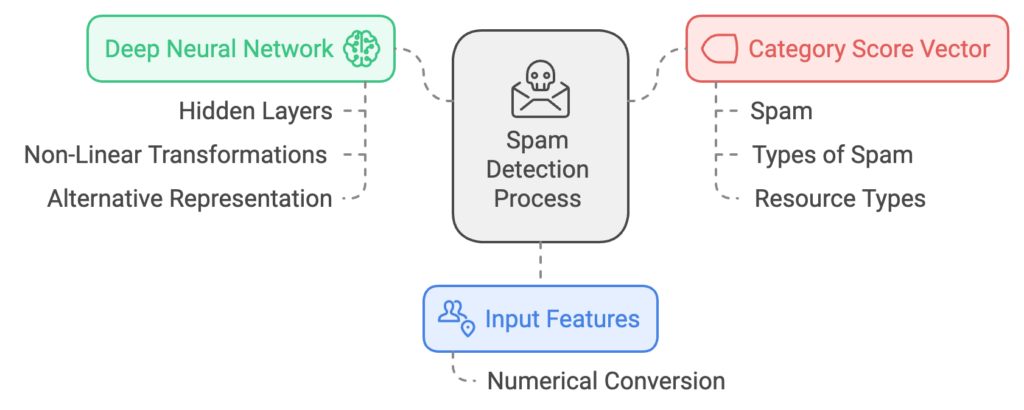
The system begins by receiving an input comprising multiple features of a resource. Each feature is essentially a value associated with a specific attribute of that resource. For instance, if the resource is a webpage, attributes could include the webpage title, content, URL, or metadata.
To process this input, the system utilizes embedding functions, which convert features into numerical values. These embedding functions are unique to each feature type, allowing the system to tailor the conversion process for optimal results.

For example, a feature representing a webpage’s title might use a different embedding function than a feature representing its URL. The output of these embedding functions is a numeric representation—often in the form of floating-point values—suitable for further analysis.
Deep Neural Network Processing
Once the features are converted to numerical values, they pass through neural network layers within a deep network. This network, inspired by the architecture of biological neural networks, applies a series of non-linear transformations to the numeric input data.
This processing is designed to generate an alternative representation of the input data, which retains all the essential characteristics of the original resource while simplifying the classification process.
Deep networks excel at handling complex and high-dimensional data, making them particularly suitable for tasks involving numerous and varied features, as is the case in internet resources. The network’s hidden layers help increase abstraction and modeling capability, improving the overall accuracy of resource classification.
Classification and Scoring
After the deep network processes the input, a classifier analyzes the alternative representation of the input data. The classifier predicts how likely it is that the resource falls into a particular category. The output is a category score vector, where each score represents the likelihood of the resource belonging to one of the pre-determined categories.
The set of categories can vary depending on the implementation. For example:
- It can include a spam category to identify and score potential search engine spam.
- It can involve a detailed breakdown into types of spam, such as content spam, link spam, or cloaking.
- It may categorize based on resource types, like news articles, blogs, forums, or shopping resources.
Applications of the Technology
Detecting and Filtering Search Engine Spam
One of the primary applications outlined in the patent is identifying and filtering out spam from search results. Spam refers to resources that manipulate search engine algorithms to gain a higher ranking than deserved.
A deep network-based classifier can accurately score the likelihood of a resource being spam. This capability enables search engines to reduce the visibility of spam resources, leading to a cleaner and more relevant search result set.
Improving Search Relevance
By categorizing resources according to specific resource types—like blogs, news, or product pages—the system allows for more relevant search results. When a user searches for a product, the search engine can prioritize product-related resources over general information pages. This targeted approach improves user satisfaction by delivering content more aligned with the user’s intent.
Indexing Decisions
The classifier’s scores can also inform decisions about whether a resource should be included in a search engine’s index. If a resource is likely to be spam, the system can exclude it from the index altogether. Conversely, resources with high relevance scores can be indexed promptly, ensuring that valuable information is accessible to users.
Explanation of Components
- Input Features: Represents the initial data extracted from internet resources, such as text, links, metadata, etc.
- Numerical Conversion: Transforms raw features into numerical values using techniques like one-hot encoding, embeddings, or normalization.
- Deep Neural Network:
- Input Layer: Receives the numerical data.
- Hidden Layers: Multiple layers that perform non-linear transformations, enabling the network to learn complex patterns.
- Output Layer: Produces the alternative representation of the input data.
- Alternative Representation: A transformed version of the input data that captures essential features in a simplified form, facilitating easier classification.
- Classifier: An algorithm (e.g., softmax layer, logistic regression) that takes the alternative representation and predicts the probability of each category.
- Category Score Vector: The final output containing scores or probabilities for each predefined category, indicating the likelihood of the resource belonging to each category.
- Categories: Different classification targets, such as identifying spam, differentiating spam types, or categorizing resource types.
Deep Network Architecture and Embedding Functions
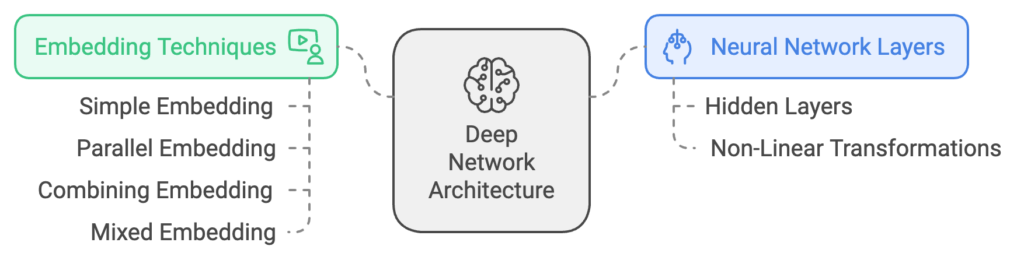
Neural Network Layers and Non-Linear Transformations
This patent describes a deep neural network with multiple layers, each performing non-linear transformations using complex mathematical operations. These processes enhance the data, allowing the classifier to make accurate predictions and effectively classify various web resources.
Embedding Techniques
A notable feature of the system is its sophisticated embedding methods:
- Simple Embedding: Converts single tokens (like words) into numeric vectors.
- Parallel Embedding: Transforms each token in a list separately and combines them into a unified vector.
- Combining Embedding: Merges tokens into a single vector using mathematical functions like averaging or weighted combinations.
- Mixed Embedding: Combines aspects of parallel and combining embeddings to generate a rich numeric representation.
These embedding functions translate textual and categorical data into formats that a neural network can process, making the data suitable for high-level classification tasks.
Practical Implementation and Benefits
Parallelized Training
The patent suggests using parallel processing techniques for training, especially when dealing with large datasets. This method can expedite training, making it feasible to create highly accurate models quickly.
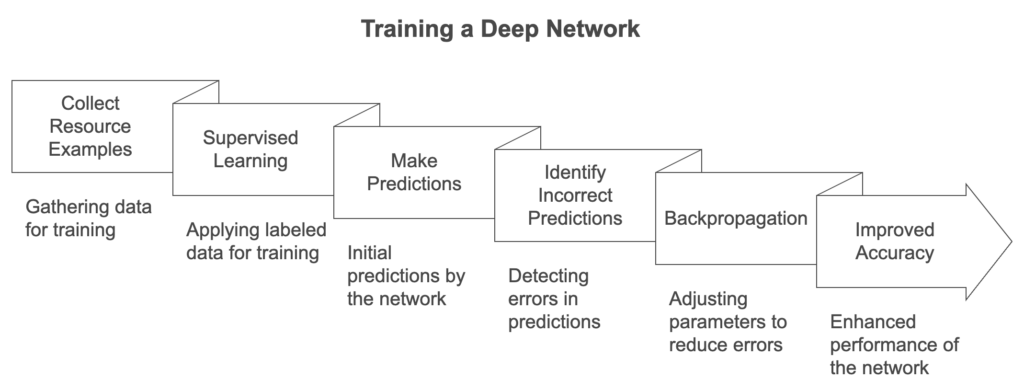
Training and Backpropagation
The deep network is trained using supervised learning on resource examples and their correct classifications. It employs backpropagation to adjust parameters when predictions are incorrect, improving accuracy and expanding its ability to handle various resource types and classification challenges.
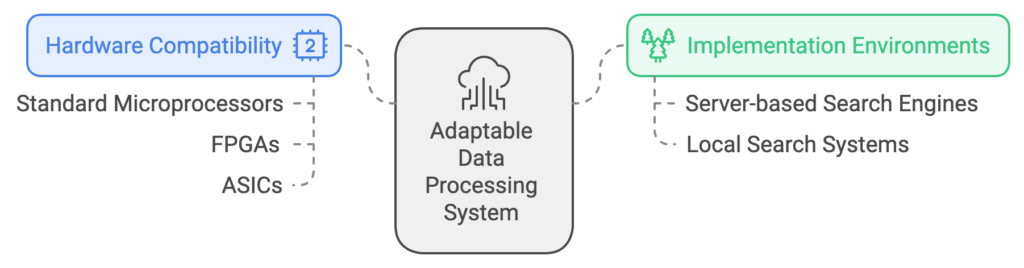
System Adaptability
The system is adaptable to various data processing hardware, from standard microprocessors to specialized circuits like FPGAs or ASICs. This flexibility allows for implementation in different environments, including server-based search engines and local search systems.
SEO Takeaways
The technology described in this patent offers several insights and implications for Search Engine Optimization (SEO):
Focus on Quality and Authenticity: With advanced classification capabilities, search engines are increasingly adept at identifying spam content. Focusing on quality, well-researched, and authentic content is essential for good search visibility.
Understanding Content Classification: The ability of deep networks to categorize content based on type underscores the importance of clear content structure. Proper use of headings, metadata, and consistent content categorization (e.g., separating blogs, product pages, and news) can help search engines better understand the nature of the content, potentially leading to higher rankings.
Leveraging Structured Data and Semantic Markup: Search engines using deep networks value structured data that clearly defines the content’s context. Implementing semantic HTML tags and structured data (like Schema.org) can provide additional clarity, helping the system categorize content more accurately. This can lead to improved indexing and ranking.
Long-Tail Keywords and Specificity: The deep network’s ability to understand nuanced categories suggests that targeting long-tail keywords—specific phrases with lower competition—can be highly effective. Such keywords are often tied to particular resource types (e.g., a niche blog or a product review), which may align with the categories the classifier uses.
Content Freshness and Resource Attributes: The patent mentions resource features like age and domain, indicating that these factors influence classification. Keeping content updated and maintaining domain authority through legitimate backlinks and high-quality content remains crucial for maintaining or improving search rankings.
Conclusion
The patent on classifying resources using a deep network highlights a sophisticated approach to refining search engine capabilities. By implementing deep learning models and advanced neural networks, the system aims to improve resource classification accuracy, enhance the relevance of search results, and better meet user expectations.
The SEO implications are clear: as search technology advances, the emphasis is increasingly on authentic, high-quality, and well-structured content that genuinely meets users’ informational needs.
Classifying Resources Using a Deep Network
Inventors: David C. Orr, Daniel E. Loreto, and Michael J. P. Collins
Assignee: Google LLC
European Patent Application: EP2973038A1
Published: January 20, 2016
Filed: March 13, 2014