What’s the Problem with Current Search Methods?
Traditional search methods, like using keywords, have two big problems:
- Different Words for the Same Idea (Synonymy): People often use different words to describe the same thing. For example, one person might say “car,” while another says “vehicle.” This makes it easy to miss important information if the words don’t match exactly.
- Words with Multiple Meanings (Polysemy): Some words can mean different things depending on the context. For instance, “bank” could mean a financial institution or the side of a river. This can lead to irrelevant results if the system doesn’t understand which meaning is intended.
These issues make it hard for users to get the right information because the system only looks for exact word matches, not the actual meaning behind the words.
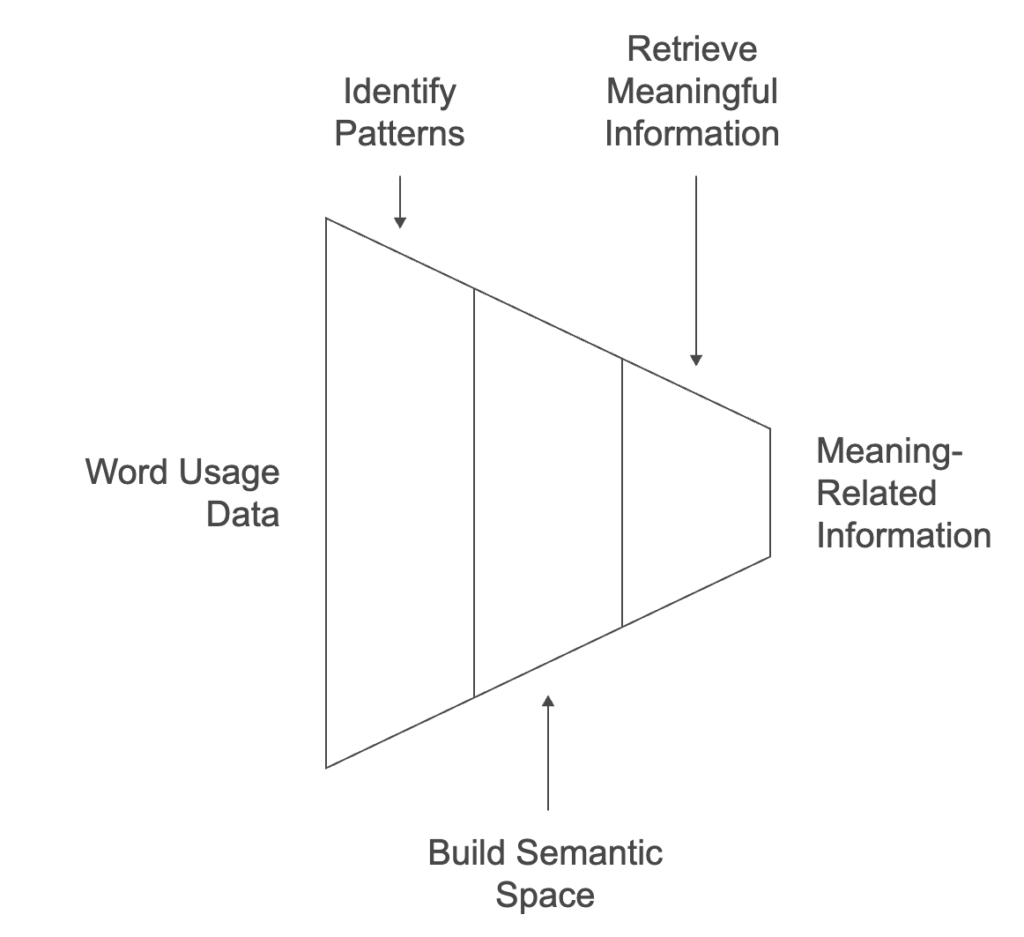
How Does This Patent Solve the Problem?
The invention uses a mathematical approach to look for the deeper meaning behind words instead of just matching them exactly. It does this by:
- Finding patterns in how words are used in documents.
- Building a semantic space where both the words and the documents are represented by their meanings, not just their literal words.
- Using this space to retrieve information that’s related in meaning, even if the exact words don’t match.
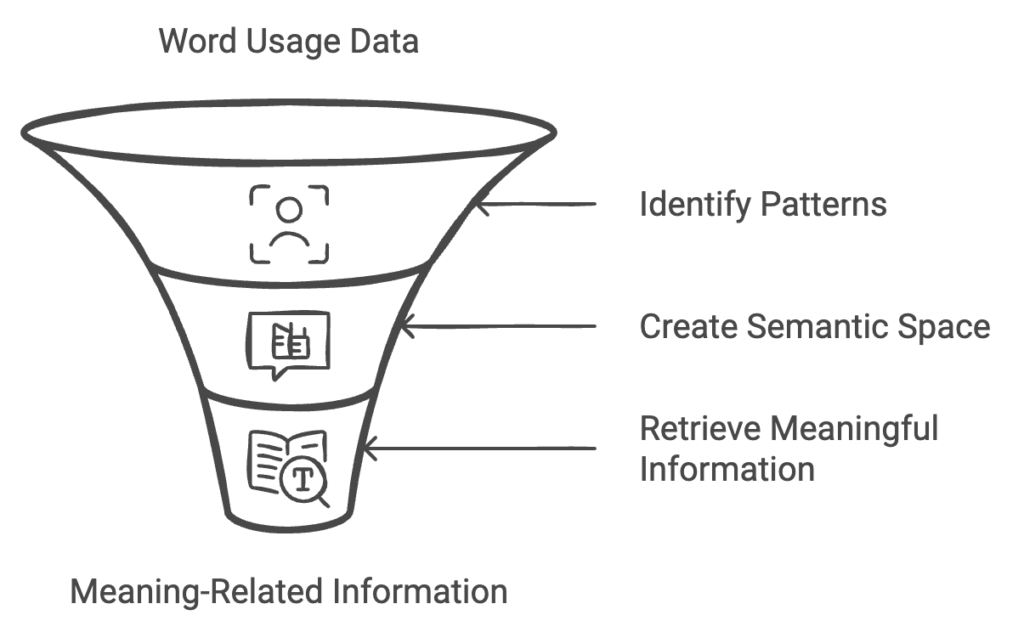
An Example of How It Works
Imagine you have a list of document titles. If you search for “human-computer interaction,” regular keyword search might only return documents that have those exact words. However, this system can recognize documents that are about the same topic, even if they don’t use those exact terms.
Why is This Better?
- It helps users find information based on meaning, not just words.
- It handles different words people use for the same idea and words that have multiple meanings.
- It’s automatic, so there’s no need to create a manual list of synonyms or special keywords.
Example: Finding Related Documents
The document titles and the words in them have been chosen to demonstrate how the invention works. Imagine we make a two-dimensional map to show the relationships between words and documents. This map is created using a mathematical process called singular value decomposition.
- Words are represented as circles, and document titles are shown as squares.
- Documents about graph theory cluster together in one part of the map, while documents about human-computer interaction cluster in another part.
How the Search Works
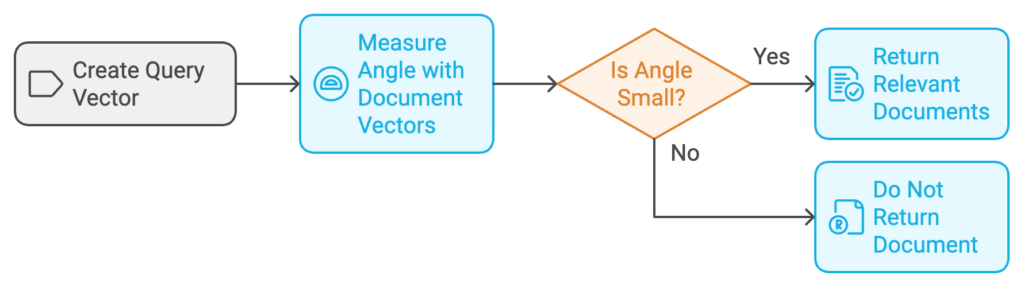
If a user searches for “human-computer interaction“:
- The search terms (“human” and “computer”) are used to create a query vector.
- This vector points in a direction that is an average of these terms on the map, shown by an arrow labeled “Q” in Figure 1.
- We measure the angle between the query vector and the document vectors to determine which documents are relevant. The smaller the angle, the more similar they are.
In this example, two documents (c3 and c5) are returned as matches even though they don’t use the same exact words as the search query. This is possible because the method looks at the overall pattern of term usage across all the documents, revealing hidden relationships.
What is Singular Value Decomposition?
SVD is a mathematical technique for breaking down large datasets into simpler components while still retaining the essential information. In information retrieval, SVD processes text data to understand relationships between words and documents in a way that goes beyond simple keyword matching.
Think of SVD as a way to transform a complex dataset into a set of core ideas or patterns, which allows us to capture the underlying meaning of the data while ignoring less important details. It’s particularly useful for organizing information in a way that makes it easier to retrieve relevant content.
How Does SVD Work in Information Retrieval?
Here’s how SVD is applied in the process of retrieving information:
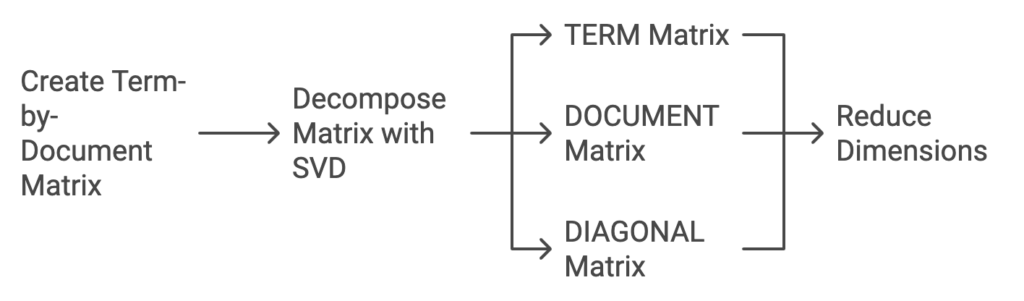
- Creating a Term-by-Document Matrix:
- Imagine you have a large collection of documents, and each document contains many words.
- We first create a term-by-document matrix, which is like a table that shows how frequently each word (term) appears in each document.
- For example, if you have five documents and ten unique words, the matrix will have ten rows (words) and five columns (documents). Each cell shows how many times a word appears in a document.
- Breaking Down the Matrix:
- SVD is used to decompose this term-by-document matrix into three smaller matrices: TERM, DOCUMENT, and DIAGONAL.
- The TERM matrix represents the words, the DOCUMENT matrix represents the documents, and the DIAGONAL matrix contains numerical values that describe how important each dimension is (like how much information it represents).
- By breaking it down this way, we can represent the complex relationships in a simpler, multi-dimensional space.
- Reducing Dimensions:
- SVD lets us reduce the complexity by keeping only the most important components—essentially the most informative “dimensions.”
- Imagine reducing a 3D object to a 2D picture: you’re losing some details, but keeping the overall structure.
- This reduction helps us focus on the key relationships and ignore minor variations or “noise” in word usage that don’t contribute much meaning.
How Does This Help in Information Retrieval?
One major advantage of using SVD is that it allows us to retrieve relevant information based on latent meaning, rather than exact word matches. Here’s how it works:
Synonymy and Polysemy
Synonymy: Different words may mean the same thing (e.g., “car” and “automobile”). Traditional keyword searches may miss relevant content if the query uses synonyms not present in the document.
Polysemy: A single word may have multiple meanings depending on the context (e.g., “bank” could refer to a riverbank or a financial institution).
SVD captures the semantic structure of terms by analyzing the overall pattern of how terms are used across all documents. This means that it can understand relationships between words even if they aren’t explicitly stated.
Folding a Query into the Semantic Space
When a user makes a query (e.g., “human-computer interaction”), we map the words in the query into the same simplified space we created with SVD.
The query is treated as a vector, and its position in the space is calculated based on the meanings of the words in it.
Then, we can calculate how close this query vector is to each document vector in the same space.
If a document has a high cosine similarity (which measures the angle between two vectors), it means the document is relevant to the query.
Retrieving Hidden Relationships
Suppose there are two documents, and one is about “user interface” and the other is about “computer systems,” but neither document explicitly uses the term “human-computer interaction.”
SVD can determine that these documents are related to the concept of human-computer interaction because of how these terms are used across other documents.
This allows the system to return results that are highly relevant even though they don’t share the exact words with the query.
Why is This Important?
The key benefit of SVD in information retrieval is that it makes searches more meaningful and effective:
- Overcomes Keyword Limitations: Users often do not use the exact keywords needed to find relevant documents. SVD helps understand the meaning behind the words and returns results accordingly.
- Groups Similar Content: By reducing the dataset to a smaller set of dimensions, we can see clear clusters of documents or terms that are conceptually related, even if they don’t share exact words.
- Improves User Experience: Since the system can understand the meaning, users are more likely to get relevant documents without having to refine their search over and over again.
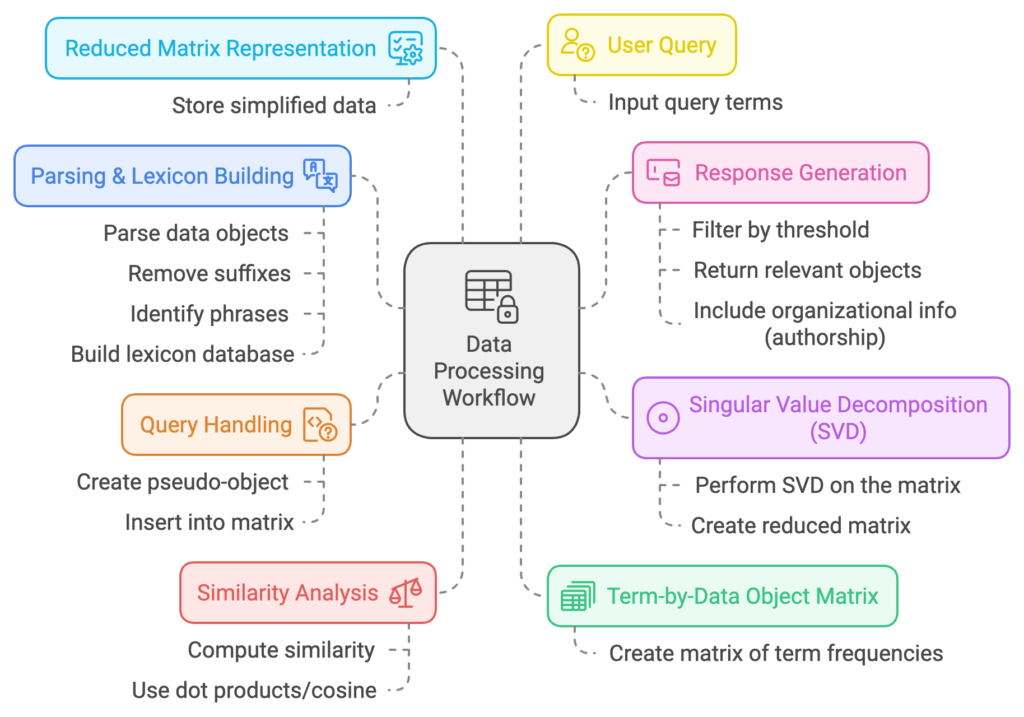
These claims describe an information retrieval system that utilizes advanced mathematical processing, specifically Singular Value Decomposition (SVD), to enhance the retrieval of information from large databases. Here’s a simplified summary of the key steps involved in these claims:
- Term-by-Data Object Matrix Creation: The system first creates a matrix called the term-by-data object matrix. This matrix represents how often certain terms appear in different files (data objects) stored in a computer system.
- Singular Value Decomposition: The matrix is then processed using Singular Value Decomposition (SVD) to create a reduced matrix representation. This step allows the system to retain the essential patterns and relationships in the data, while reducing noise and making it easier to find underlying meanings.
- Handling User Queries: When a user submits a query, the system creates a pseudo-object based on the terms in the query. This pseudo-object is then inserted into the matrix. The system analyzes the similarity between the pseudo-object and the other data objects by evaluating mathematical relationships (such as dot products or cosines) to generate the most relevant information as a response to the user.
- Lexicon and Parsing: The system also involves building a lexicon database to define selected terms. This is done by parsing the data objects, removing unnecessary suffixes (like plurals), and identifying phrases to ensure the matrix is accurate and meaningful.
- Similarity Analysis and Response Generation: The system computes the similarity between the query (represented by the pseudo-object) and the stored documents. It measures similarity using mathematical techniques, such as dot products or cosine similarities. Only data objects with a similarity score above a certain threshold are returned as relevant matches to the user’s query.
- Reduced Matrix Representation: During the SVD process, a reduced matrix representation captures the most significant associations. This reduced representation makes it easier to identify related terms and documents, helping to make faster and more accurate comparisons by filtering out less relevant information.
- Organizational Database: The system can also incorporate information about document authorship, meaning that when generating a response, it might provide additional organizational information, such as who wrote the document or group information.
Practical Outcome
This process allows the information retrieval system to go beyond exact keyword matching and to identify documents that are conceptually relevant even if they do not contain the exact keywords used in the user’s query. The use of latent semantic relationships through SVD enables the system to understand the deeper meanings behind words, providing more accurate and contextually relevant search results.
The system, therefore, creates a more advanced search experience by understanding the underlying semantic meaning in text and offering efficient and relevant information retrieval that takes into account the complexity of human language, including synonyms and context.
SEO Takeaways
The patent offers valuable insights for improving SEO by focusing on semantic relevance, quality, and user intent. Here are the key takeaways:
- Latent Semantic Indexing (LSI): Use LSI keywords, synonyms, and related terms to enhance semantic relevance. Avoid excessive keyword repetition and instead cover related subtopics comprehensively.
- Content Quality and Structure: Content quality is defined by its depth and relevance rather than keyword density. Structure your content clearly with headings and subheadings to signal semantic relationships.
- Synonymy and Polysemy: Address different ways users search for the same concept. Include diverse phrases and keywords to target various user intents, while avoiding keyword over-reliance.
- Entity and Topic Association: Create topic clusters and interlink related content to establish authority. Focus on comprehensive topic coverage instead of targeting individual keywords.
- Content Personalization: Craft content that matches different user intents—informational, navigational, and transactional. Use tools like “People Also Ask” to understand user queries.
- Avoid Over-Optimization: Ensure content is natural and informative rather than forced and keyword-stuffed.
- Anchor Text Optimization: Use descriptive, contextually relevant anchor text to improve discoverability.
- Query Representation: Write content that aligns with user questions and phrases. Use meta descriptions and schema markup for structured data representation.
- User-Centric Language: Use language that matches how your audience phrases their queries. Align your content with users’ natural language to improve ranking.
Conclusion
Modern SEO requires focusing on semantic relevance, user intent, and quality content. By optimizing for LSI, diversifying language, creating topic clusters, and making content user-centric, your chances of ranking well increase, as search engines favor meaningful and contextually rich content over exact keyword matches.
Computer information retrieval using latent semantic structure
Inventors: Scott C. Deerwester, Susan T. Dumais, George W. Furnas, Richard A. Harshman, Thomas K. Landauer, Karen E. Lochbaum, and Lynn A. Streeter
Assigned to: Bell Communications Research, Inc.
US Patent: 4,839,853
Granted: June 13, 1989
Filed: September 15, 1988