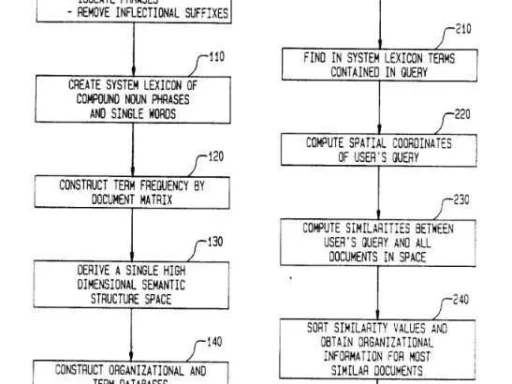
The Google patent, “Generating Query Answers,” introduces a method for generating natural language responses to factual queries by utilizing structured data and applying constraints to select the most appropriate templates for constructing answers. This patent has significant implications for search engine optimization (SEO), especially in the context of semantic search and entity-based optimization.
Explanation of the Patent
At its core, the patent describes a system that:
1. Receives a user’s factual query—which could be voice input or text—that identifies attributes of an entity (e.g., “How old is [Entity]?”).
2. Accesses a database of facts—stored in a structured format like a graph database containing entities and their relationships, often represented as triples (entity-attribute-value).
3. Utilizes candidate templates—predefined sentence structures with fields (placeholders) associated with specific constraints (e.g., type, temporal, gender) to generate natural language responses.
4. Select the most suitable template by matching the constraints of the template fields with the available factual data, aiming to use the template that satisfies the maximum number of constraints.
5. Generates a natural language answer—by filling in the template fields with the appropriate data, resulting in a grammatically correct and contextually relevant sentence.
6. Communicates the answer to the user—which could be in text form or converted to speech for voice assistants.
Key Components:
- Constraints are rules associated with template fields that ensure the inserted data makes sense in the context (e.g., a date must be in the past, and a name must match the gender).
- Templates: Predefined sentence structures that can be filled with data to form natural language answers.
- Graph Database: A structured data repository where entities and their relationships are stored in a way that can be efficiently queried.
Key Advancements in Natural Language Processing Systems
- Enhanced Natural Language Responses: The system aims to provide more natural and conversational answers, improving user experience, especially in voice-based interactions.
- Real-Time Data Updates: By using a graph that can be updated in real-time, the system ensures that the information provided is current and accurate.
- Scalability and Flexibility: Templates and constraints allow the system to handle various queries without needing hard-code responses.
- Semantic Understanding: The focus on entities and their attributes indicates a shift towards semantic understanding in search, moving beyond keyword matching.
- Separation of Data and Language Processing: The system decouples the database of facts from the language generation mechanism, allowing for independent updates and maintenance.
The “Generating Query Answers” patent highlights Google’s ongoing efforts to enhance the way search engines process and respond to user queries by leveraging structured data and semantic understanding. By focusing on entities, their attributes, and the relationships between them, Google aims to provide more accurate and natural language responses to users.
Overview of the System Workflow

Explanation:
- User Query: The user submits a factual query, possibly in natural language or via voice input (e.g., “Who was Woody Allen married to?”).
- Query Processing: The system parses the query to identify the entity (e.g., “Woody Allen”) and the attribute(s) (e.g., “marriages”).
- Data Retrieval: The system accesses a structured database (graph database) to retrieve relevant facts (triples) about the entity.
- Template Selection: The system accesses candidate templates suitable for the attribute(s) identified.
- Constraints Application: Constraints associated with each template field are applied to determine the most appropriate template that fits the available data.
- Answer Generation: The selected template is filled with the retrieved data to generate a natural language answer.
- Response to User: The generated answer is communicated back to the user, either as text or converted to speech.
Graph Database Structure

Explanation:
- Nodes: Represent entities (e.g., “Woody Allen”, “Soon-Yi Previn”, “Louise Lasser”).
- Edges: Represent relationships or attributes (e.g., “Born On”, “Marriages”).
- Triples: Each connection forms a triple (Entity – Attribute – Value), such as (“Woody Allen” – “Born On” – “Dec 1, 1935”).
Template Selection and Constraints Application
Candidate Templates for “Marriages”:
- Template A: <Entity> has been married to <Spouse> since <Date>.
- Constraints:
- <Spouse> must be an entity with a spouse relationship.
- <Date> must be a past date.
- Constraints:
- Template B: <Entity> was married to <Spouse> from <Start Date> to <End Date>.
- Constraints:
- <Spouse> must be an entity with a spouse relationship.
- <Start Date> and <End Date> must be past dates.
- Constraints:
- Template C: <Entity> is married.
- Constraints:
- No additional data is required.
- Constraints:
Data Retrieved:
- Marriage 1:
- <Entity>: Woody Allen
- <Spouse>: Soon-Yi Previn
- <Date>: 1997 (Married since 1997)
- Marriage 2:
- <Entity>: Woody Allen
- <Spouse>: Louise Lasser
- <Start Date>: 1966
- <End Date>: 1970
Template Selection Process:
- For Marriage 1:
- Template A fits all constraints.
- For Marriage 2:
- Template B fits all constraints.
Explanation:
- The system selects the templates that satisfy the maximum number of constraints based on the available data.
- By applying constraints, the system ensures that the generated answer is accurate and grammatically correct.
Answer Generation
Selected Templates Filled with Data:
- Phrase 1 (Marriage 1):
- “Woody Allen has been married to Soon-Yi Previn since 1997.”
- Phrase 2 (Marriage 2):
- “He was married to Louise Lasser from 1966 to 1970.”
Combining Phrases into a Final Answer:
- “Woody Allen has been married to Soon-Yi Previn since 1997 and was previously married to Louise Lasser from 1966 to 1970.”
Explanation:
- The phrases generated from the selected templates are combined to form a coherent and comprehensive answer.
- Pronouns or conjunctions are used as needed to improve the flow of the sentence.
Meta-Template Usage for Complex Queries
Meta-Template Structure for Person Entity:
<Entity> <Phrase 1> and <Phrase 2>.
Explanation:
- The meta-template serves as a higher-level template that can incorporate multiple phrases or attributes.
- This allows the system to answer queries that involve multiple attributes (e.g., “Where is Woody Allen’s hometown and alma mater?”).
Constraints Hierarchy and Types

Explanation:
- Type Constraints: Ensure the data type matches (e.g., date, number, entity).
- Temporal Constraints: Ensure the time-related data makes sense (e.g., dates in the past for birth dates).
- Gender Constraints: Ensure pronouns and descriptors match the entity’s gender.
Example of Query Processing
User Query: “How old is Woody Allen?”
Processing Steps:
- Extracted Entity: Woody Allen
- Extracted Attribute: Age
- Data Retrieved:
- Date of Birth: December 1, 1935
- Candidate Templates:
- Template A: <Entity> was born on <Date> and is currently <Age> years old.
- Constraints:
- <Date> must be a past date.
- <Age> must be a calculated value.
- Constraints:
- Template A: <Entity> was born on <Date> and is currently <Age> years old.
- Constraints Application:
- All constraints satisfied using the retrieved date of birth.
- Answer Generated:
- “Woody Allen was born on December 1, 1935, and is currently 86 years old.”
Detailed Breakdown of Constraints Application
Constraints Table:
|
Template Field |
Required Constraint |
Data Available |
Constraint Satisfied? |
|
<Entity> |
Entity Name |
Woody Allen |
Yes |
|
<Date> |
Past Date |
Dec 1, 1935 |
Yes |
|
<Age> |
Calculated Number |
86 |
Yes |
Explanation:
- The system verifies that all constraints for each field are satisfied before selecting the template.
- If any constraint is not satisfied, the system moves to the next best template.
Handling Multiple Attributes
User Query: “What is the capital of France and its population?”
Processing Steps:
- Extracted Entity: France
- Extracted Attributes: Capital, Population
- Data Retrieved:
- Capital: Paris
- Population: 67 million
- Candidate Templates for Capital:
- <Entity>’s capital is <Capital>.
- Candidate Templates for Population:
- <Entity> has a population of <Population>.
- Meta-Template:
- <Phrase 1> Additionally, <Phrase 2>
- Generated Phrases:
- Phrase 1: “France’s capital is Paris.”
- Phrase 2: “It has a population of 67 million.”
- Final Answer:
- “France’s capital is Paris. Additionally, it has a population of 67 million.”