Initially filed in 2003, a granted Google patent sheds light on topics like anchor text indexing, crawling frequencies, and the treatment of redirects. It offers intriguing insights, though it’s worth noting that the patent may not reflect current practices.
Over time, Google’s methods could have evolved. It’s well-known that different web pages experience varying crawl rates and indexing speeds, and anchor text in hyperlinks can significantly affect a page’s ranking in search results. The patent explores how these elements interact, potentially revealing strategies once used to determine page rankings.
Why rely on anchor text indexing to determine relevance?
When users search, they expect a concise list of highly relevant pages, but older search engine systems only indexed the contents of the page itself. According to the authors of this anchor text indexing patent, valuable information about a page can be found in the hyperlinks pointing to it. This is especially useful when the target page has minimal or no text, such as in the case of images, videos, or software.
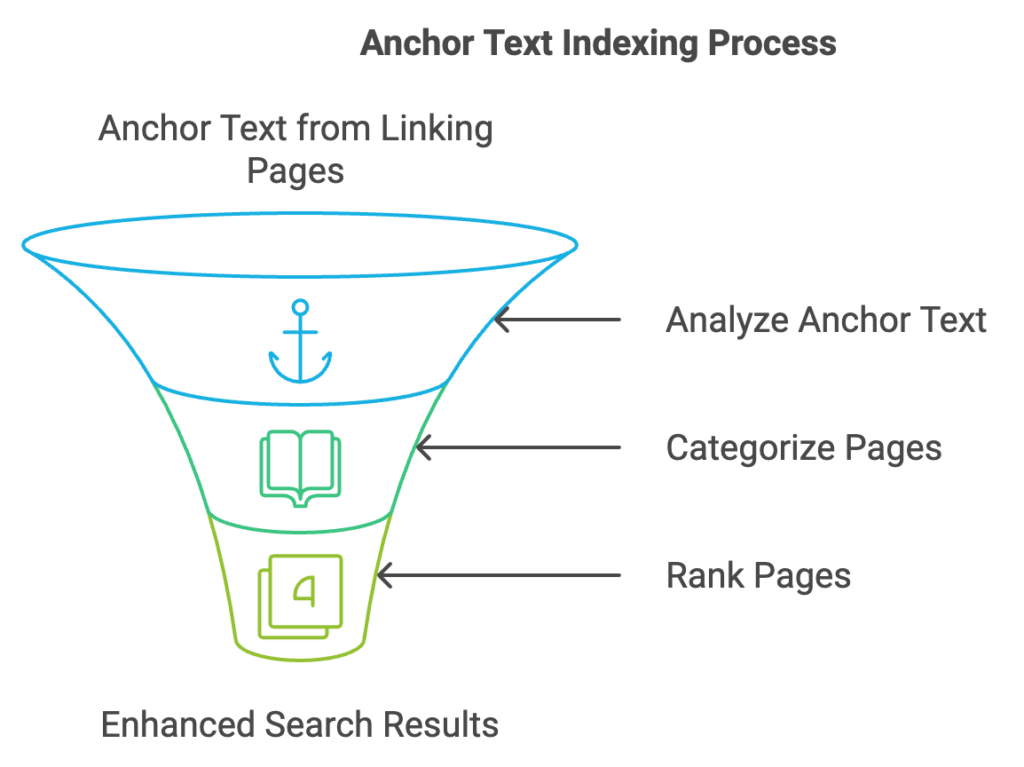
Often, the anchor text on linking pages provides the only descriptive information for these types of content. Additionally, anchor text indexing allows search engines to rank and categorize pages even before they are crawled, enhancing the efficiency and accuracy of search results.
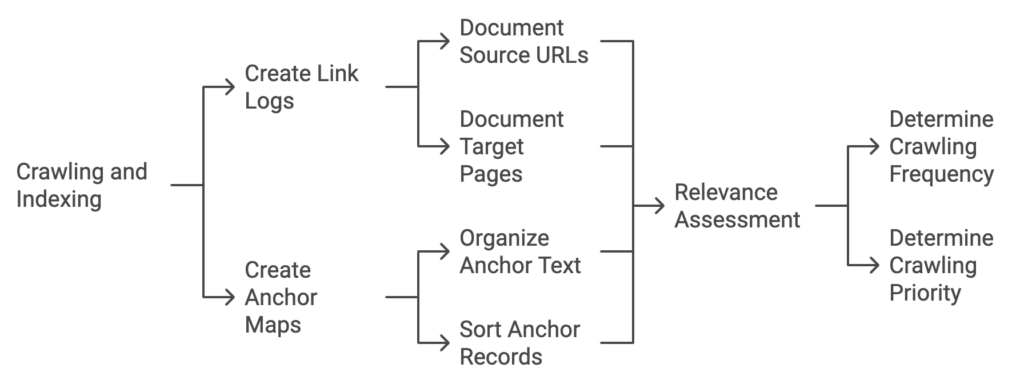
Creating Link Logs and Anchor Maps
Creating link logs and anchor maps is a central aspect of the process outlined in the patent. The link log captures numerous link records during crawling and indexing, documenting the source URLs and the target pages linked to them.
URL Discovery in Anchor Text Indexing
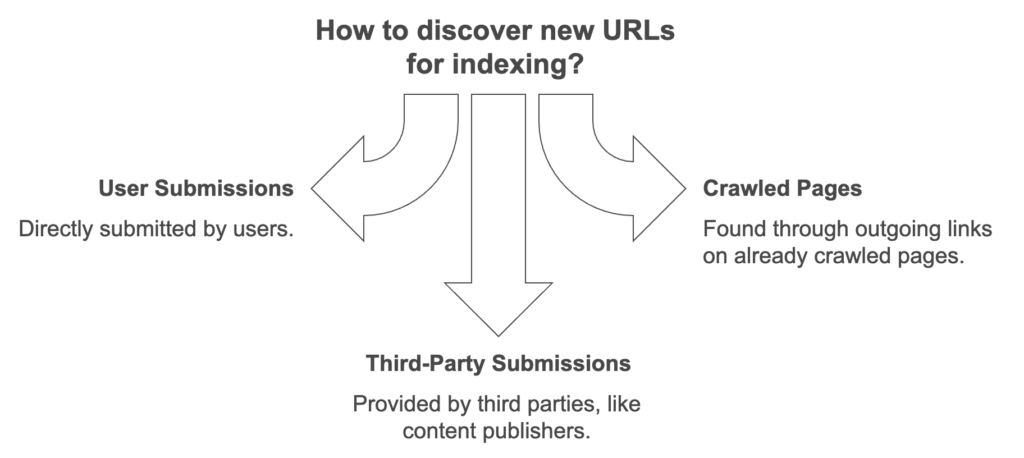
The sources for discovering URLs in the data structure include several key methods:
- User Submissions: URLs directly submitted by users to the search engine system.
- Crawled Pages: URLs found through outgoing links on already crawled pages.
- Third-Party Submissions: URLs provided by third parties, such as content publishers, who submit links as they are published, updated, or changed—often through sources like RSS feeds.
This explains why it’s common to see newly published blog posts appearing in search results just a few hours after being posted, as they may be part of the real-time layer or submitted through an RSS feed for rapid indexing.
Determining What URLs Are Placed in Which Layers
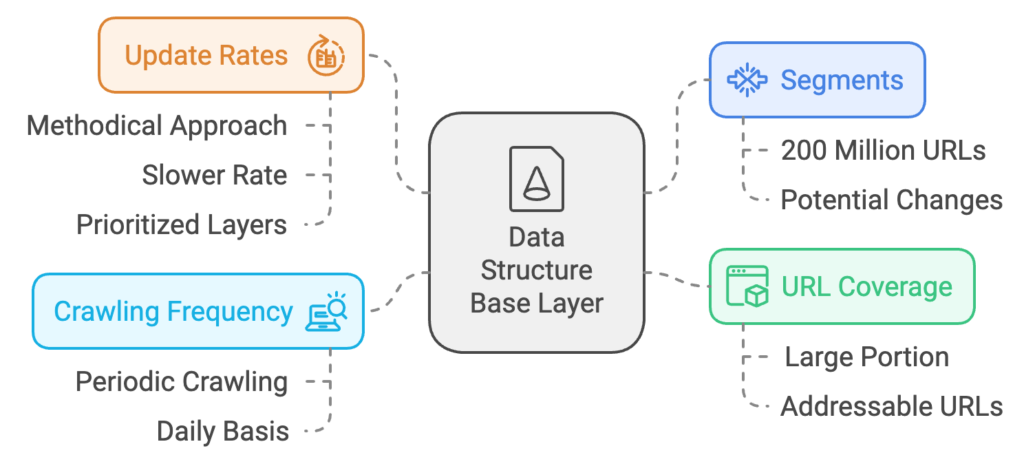
The placement of URLs in different layers can be determined by calculating a daily score for each URL, which is given by the formula: daily score = [PageRank]² * URL change frequency. This score helps decide which URLs receive more frequent crawling.
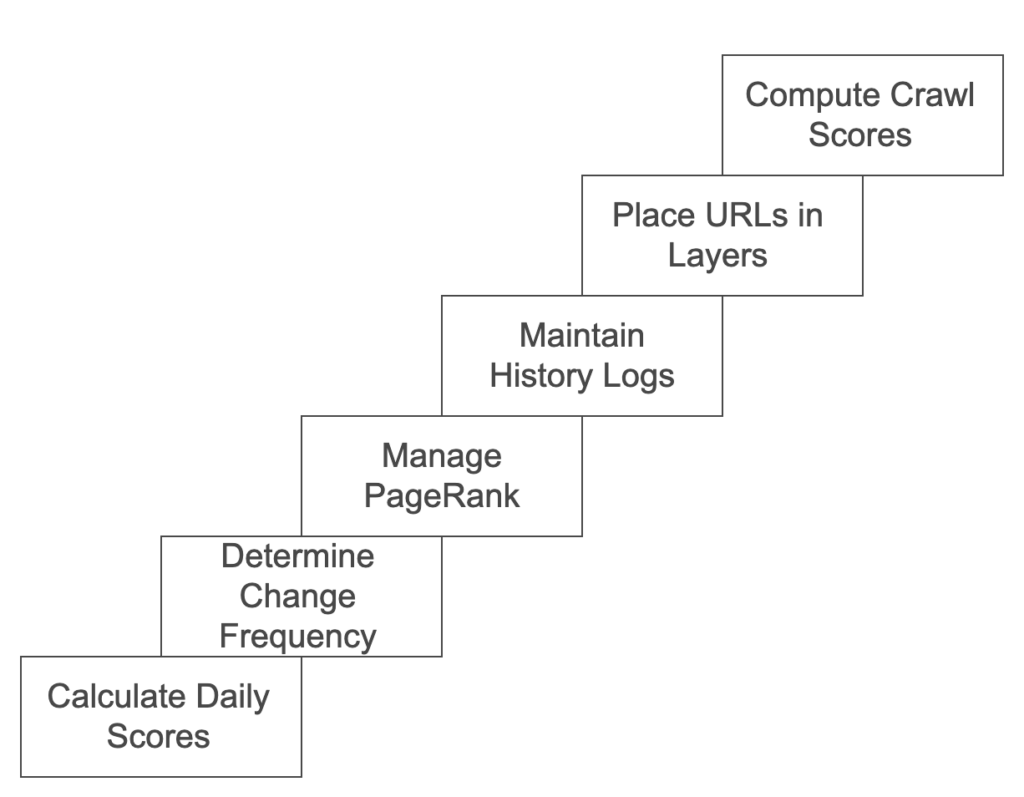
URL Change Frequency Data: When a robot accesses a URL, content filters evaluate if the content has changed since it was last accessed. This information is stored in history logs and used by the URL scheduler to compute the change frequency and determine crawling rates.
PageRank: A query-independent score, also known as a document score, is calculated for each URL by examining the number of URLs linking to it and the PageRank of those linking pages. Higher PageRank URLs may receive more frequent crawling. This PageRank data is managed by URL managers.
URL History Log: This log stores information on URLs, including those no longer part of the data structure, such as URLs that are defunct or excluded from crawling upon request by a site owner.
Placement into Base Layer: When a URL is placed in the base layer, the URL scheduler ensures a random or pseudo-random distribution across segments, ensuring an even allocation of URLs.
URL Layer Placement and Random Distribution: URLs are distributed into appropriate layers—base, daily, or real-time—using processing rules that aim for balanced segment allocation.
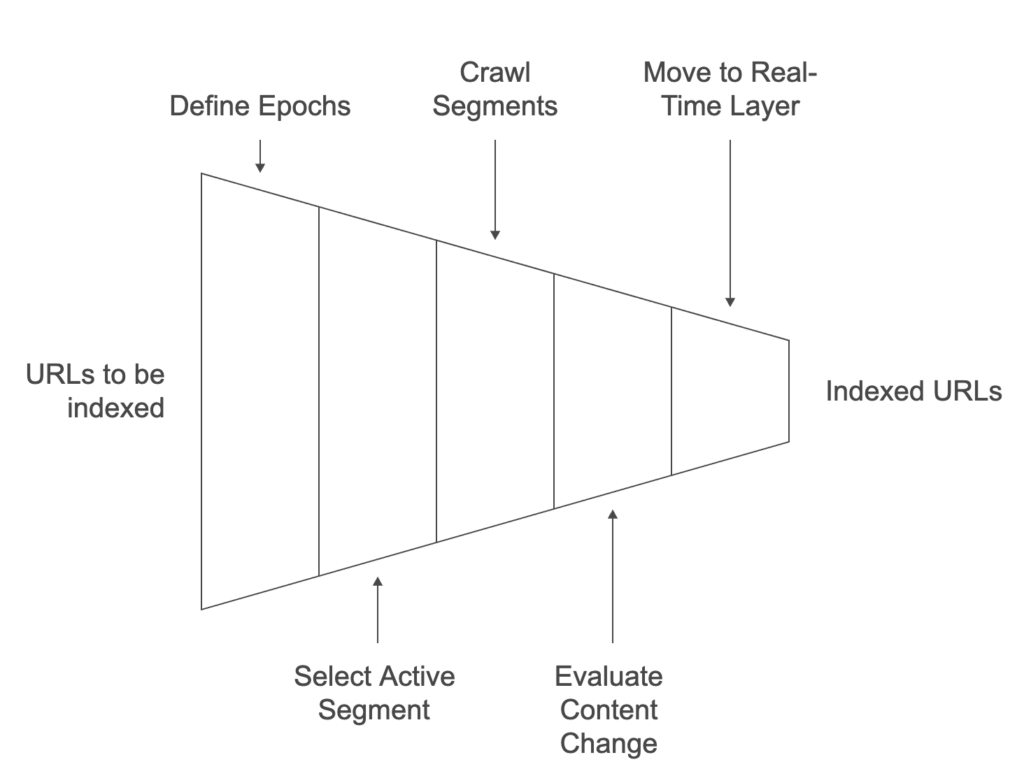
Handling Situations Where All URLs Cannot Be Crawled in an Epoch:
- Crawl Score Calculation: A crawl score is computed for each URL in different segments and layers, and only those with high scores are passed to URL managers.
- Optimum Crawl Frequency: The URL scheduler determines the optimal crawl frequency for each URL, and URL managers use this information to decide which URLs to crawl.
These methods can be applied individually or combined to prioritize URLs for crawling.
Factors Determining a Crawl Score: The crawl score helps decide whether a URL proceeds to the next stage during an epoch. It considers:
- Current Location of the URL (active segment, daily layer, or real-time layer).
- URL PageRank.
- URL Crawl History: This can be calculated as crawl score = [PageRank]² * (change frequency) * (time since last crawl).
How the Crawling Score Might Be Affected
Up-weighting Crawl Scores: URLs that haven’t been crawled in a significant period may have their crawl score increased to ensure they are revisited within a set minimum refresh time, like two months.
Setting Crawl Frequency: The URL scheduler sets and adjusts the crawl frequency for URLs in the data structure. This frequency is determined based on factors like the historical change frequency and PageRank of a URL. URLs in the daily and real-time layers generally have shorter crawl frequencies compared to those in the base layer, ranging from as frequent as every minute to as infrequent as several months.
Dropping URLs: URLs are periodically removed from the data structure to make room for new entries. This decision is based on a “keep score,” which could be a URL’s PageRank. URLs with lower scores are removed first as new URLs are added to the system.
Crawl Interval: The crawl interval is the target frequency for crawling a URL, such as every two hours. The URL manager schedules crawling based on these intervals, influenced by criteria like URL characteristics and category.
Representative URL Categories: URLs are categorized into groups such as news URLs, international URLs, language-specific URLs, and file types (e.g., PDF, HTML, PowerPoint). This helps determine crawling priorities and policies.
URL Server Requests: Sometimes, the URL server will request specific types of URLs from URL managers. These requests can be based on preset policies, such as aiming for a mix like 80% foreign URLs and 20% news URLs.
Robots: Crawling robots are responsible for visiting and retrieving documents at specific URLs. They also recursively gather documents linked from each page. Robots are assigned tasks by the URL server and submit retrieved content to content filters for further processing.
Crawling Pages Following the URL Scheduler
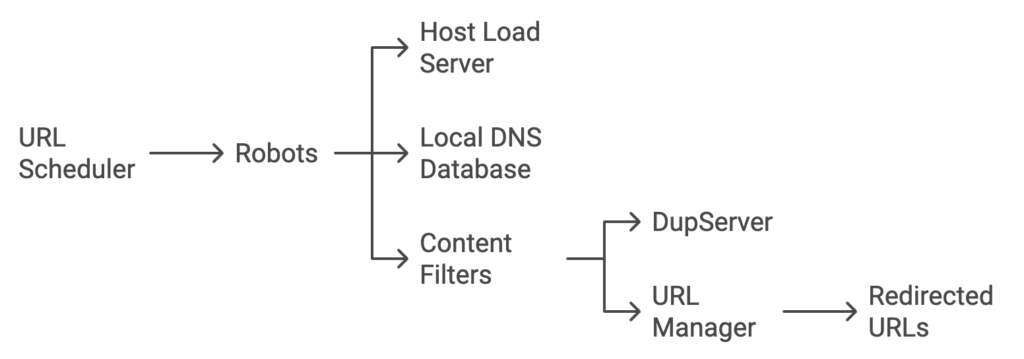
Role of the URL Scheduler: The URL scheduler decides which pages to crawl as directed by the URL server. The server receives URLs from content filters, while robots execute the crawling process. Unlike standard web browsers, robots do not automatically retrieve embedded content, such as images, nor do they follow permanent redirects.
Host Load Server: A host load server helps prevent overloading target servers by managing the rate at which robots access them.
Avoiding DNS Bottleneck Problems: To avoid DNS lookup delays, a dedicated local DNS database stores previously resolved IP addresses. This helps ensure domain names do not need repeated resolution every time a robot visits a URL.
Handling Permanent and Temporary Redirects: Robots do not follow permanent redirects directly. Instead, they send both the original and redirected URLs to content filters, which add them to link logs. These logs are then managed by URL managers, who decide if and when a robot should crawl the redirected URLs. In contrast, robots do follow temporary redirects to collect page information.
Content Filters: After robots retrieve page content, it is processed by content filters, which then send information to a DupServer to identify duplicate pages. The filters analyze:
- URL Fingerprint: A unique identifier for the URL.
- Content Fingerprint: A unique identifier for the content.
- PageRank: The rank assigned to the page.
Redirect Indicator: Whether the page serves as a source for a temporary or permanent redirect.
Rankings of Duplicate Pages
This detailed processing system helps ensure efficient crawling and indexing while minimizing redundancy in the search engine’s database.
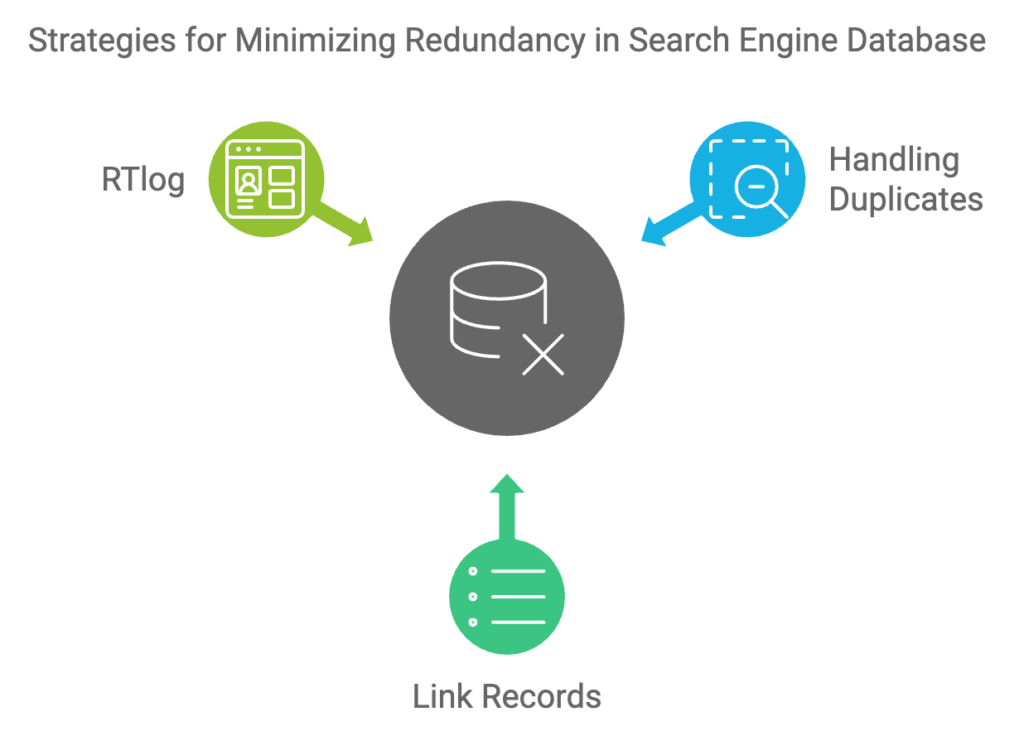
Handling Duplicates: When duplicates are detected, their page rankings are compared, and the “canonical” page is chosen for indexing. Non-canonical pages are not indexed but may have entries in the history log, and the content filter stops processing them. The DupServer also manages both temporary and permanent redirects that robots encounter during crawling.
Link Records and Surrounding Text: The link log contains one record per URL document, capturing the URL fingerprints of all links found in the document along with surrounding text. For example, a link to an image of Mount Everest might say, “to see a picture of Mount Everest, click here.” In this case, the anchor text is “click here,” but the surrounding text, “to see a picture of Mount Everest,” is also recorded. This expands the context of anchor text indexing to include nearby descriptive text.
RTlog for Matching PageRanks with Source URLs: An RTlog stores documents retrieved by robots, paired with the PageRank of their source URLs. For example, if a document is obtained from URL “XYZ,” it is stored with the PageRank assigned to “XYZ” as a pair in the RTlog. There are separate RTlogs for each layer: the active segment of the base layer, the daily layer, and the real-time layer. This structure ensures efficient tracking of documents and their relative importance for ranking purposes.
The Creation of Link Maps
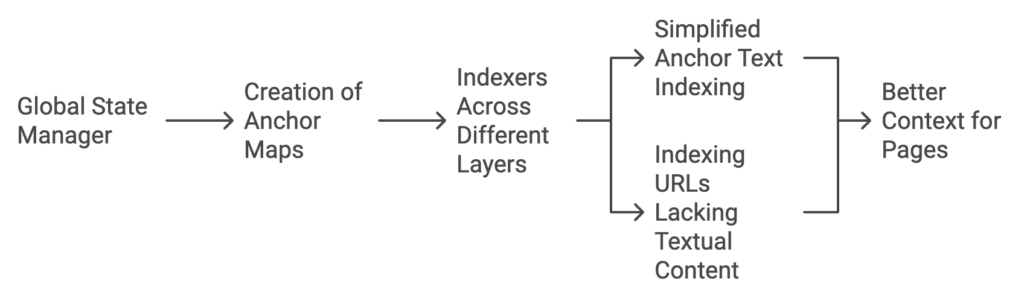
Creation of Link Maps: The global state manager reads the link logs and uses this information to generate link maps and anchor maps. Unlike link logs, the records in the link map have their text removed. Page rankers use these link maps to adjust the PageRank of URLs within the data structure, and these rankings are preserved across different epochs.
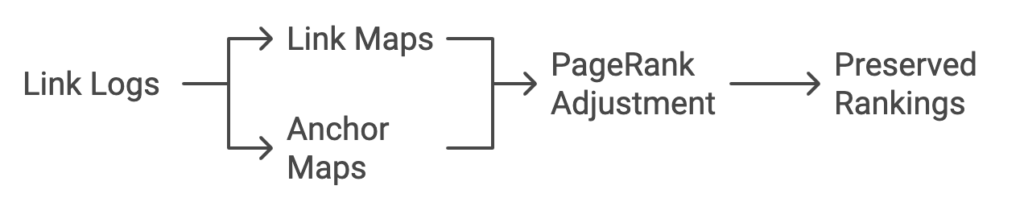
Creation of Anchor Maps: Anchor maps are also created by the global state manager. These maps are used by indexers across different layers to simplify anchor text indexing and help in indexing URLs that lack textual content, providing better context for pages with minimal on-page text.
Text Passages in Link Logs: Each record in the link log includes a list of annotations, such as the text from anchor tags pointing to a target page. These annotations can include continuous blocks of text from the source document, termed text passages. Additionally, annotations might also contain text that is outside of the anchor tag but is within a predetermined distance of the anchor tag in the document. This distance is based on factors like the number of characters in the HTML code, placement of other anchor tags, or other predefined anchor text identification criteria.
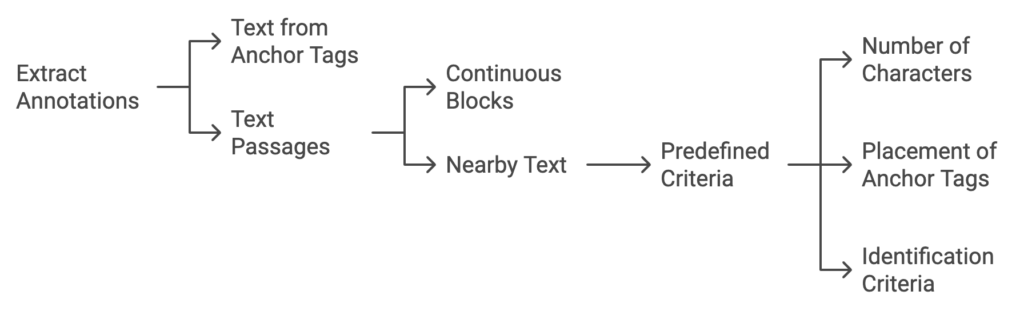
Other Annotations: Annotations may also include attributes associated with the text. For HTML text, these attributes can include formatting tags like:
- Emphasized Text (
<em>) - Citations (
<cite>) - Variable Names (
<var>) - Strongly Emphasized Text (
<strong>) - Source Code (
<code>)
Additional attributes may indicate the text position, number of characters, word count, and more. In some cases, annotations serve as delete entries, indicating that a link has been removed, as determined by the global state manager.
Anchor Text Indexing from Duplicates
Sometimes, anchor text pointing to duplicate pages is used to index the canonical version of the page. This can be especially useful if links to non-canonical pages have anchor text in a different language, enriching the context of the canonical page.
Conclusion
Google’s anchor text indexing and page crawling processes, as described in the patent, provide an intricate look into how search engines decide what content to prioritize and how URLs are organized and processed. The multi-layered crawling system, which includes base, daily, and real-time layers, ensures a balance between broad web coverage and the frequent updating of high-priority content. By calculating factors such as PageRank, change frequency, and crawl scores, Google’s approach aims to maximize the relevance and freshness of indexed pages.
The patent’s description of link maps, anchor maps, and annotations underscores the importance of link relationships and contextual information. These link structures not only contribute to determining a URL’s ranking but also help in indexing content that may lack on-page text. Handling duplicates and redirects efficiently ensures that only the most authoritative version of content is indexed, while annotations provide rich data to enhance the indexing process.
These advanced mechanisms reflect the dynamic nature of the web, where content changes frequently, and users demand up-to-date search results. Although the processes detailed in the patent may have evolved over time, the insights offer a valuable understanding of the principles behind search indexing, crawling prioritization, and managing the vast amount of information on the internet. By leveraging such sophisticated methods, search engines are better equipped to deliver the highly relevant and timely content that users expect.
The anchor text indexing patent is:
Anchor tag indexing in a web crawler system
Invented by Huican Zhu, Jeffrey Dean, Sanjay Ghemawat, Bwolen Po-Jen Yang, and Anurag Acharya
Assigned to Google
US Patent 7,308,643
Granted December 11, 2007
Filed July 3, 2003