This paper introduces the idea of “personal knowledge graphs,” which are structured information resources focused on entities that are personally significant to an individual, even if they aren’t globally important.
Unlike general knowledge graphs that represent widely recognized entities, personal knowledge graphs capture details related to the user’s daily life.
The paper outlines key differences between personal and general knowledge graphs and explores challenges in building and utilizing personal knowledge graphs.
What Are Knowledge Graphs?
Knowledge graphs (KGs) are structured information resources about entities, their attributes, and relationships. They are used in many applications, such as search, recommendations, smart assistants, and data visualization.
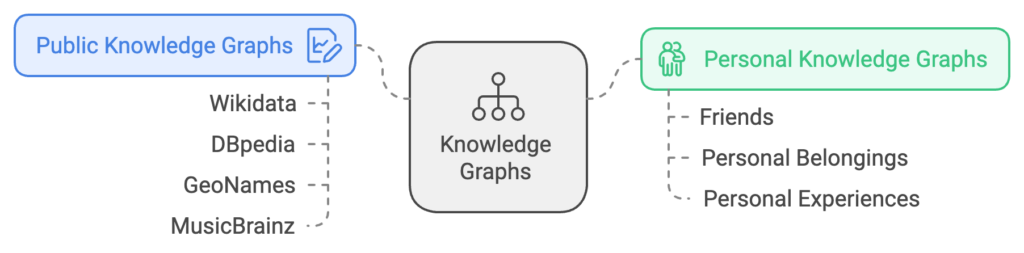
Public KGs like Wikidata, DBpedia, and domain-specific ones like GeoNames and MusicBrainz often include only prominent entities, leaving out many personal entities we interact with daily, such as friends or personal belongings.
Personal Knowledge Graphs
To address this gap, the concept of a personal knowledge graph (PKG) is introduced. PKGs are structured information resources specifically related to an individual user, including personal entities that general KGs do not cover.
PKGs have unique features: they focus on personally relevant entities, often have the user at the center, and integrate with external data sources. This makes PKGs a valuable tool for personalized services like smart assistants, which could provide more relevant answers by utilizing information specifically tied to the user.
The idea of personal knowledge graphs (PKGs) has been explored before, but previous work has mainly focused on specific subproblems, use cases, or personalized versions of existing knowledge graphs. These scattered efforts share a common goal: to make personal information available in a structured, consistent way.
Knowledge Representation
In Knowledge Representation for Personal Knowledge Graphs (PKGs), entities are structured similarly to general Knowledge Graphs (KGs), following a shared global schema. However, each entity must have a direct or indirect connection to the user, which creates a unique “spiderweb” architecture with the user at the center.
PKGs are designed to include only attributes and information relevant to the user, meaning details can often be sparse. For instance, while a general KG might include comprehensive data, a PKG focuses only on personally relevant aspects—like how the user rated a movie rather than listing all the cast members.
Temporal dynamics are also important in PKGs, as relations can be short-lived (e.g., ingredients for a planned meal), which differs from the stable relationships typically found in general KGs. Additionally, PKGs might benefit from freely defined categories to group entities, similar to Wikipedia’s use of flexible categories.
Semantic Annotation
In the Semantic Annotation of Text for Personal Knowledge Graphs (PKGs), the process of entity linking becomes more challenging compared to general Knowledge Graphs (KGs). Entity linking typically involves detecting mentions, disambiguating entities, and identifying entities that are not present in the KG (NIL-detection). General KGs have vast information available to assist these tasks, but in the case of PKGs, there may be little to no information about personal entities for algorithms to use.
For instance, personal entities like “my guitar” or “Jamie” are unlikely to have a digital presence or appear in widely accessible sources, unlike more prominent entities that might appear in news articles or have Wikipedia profiles. Thus, linking personal entities in PKGs can be considered as part of “long tail” entity linking, which deals with less common or niche entities.
NIL-detection, which deals with entities not present in an existing KG, is especially relevant for PKGs since personal entities are often encountered for the first time. These entities may not exist in the user’s PKG yet, and they may or may not exist in other KGs. Unlike traditional KGs, PKGs may need to handle general nouns or phrases (e.g., “my guitar”) rather than just proper nouns.
Population and Maintenance
In the Population and Maintenance of Personal Knowledge Graphs (PKGs), populating and maintaining data presents unique challenges compared to general Knowledge Graphs (KGs). For general KGs, population is achieved by adding data from external sources or making inferences to predict relations, while maintenance involves verifying facts and ensuring completeness. These tasks are typically overseen by human curators, such as volunteers or knowledge editors, who follow strict guidelines.
However, in PKGs, there are no curators. Therefore, it is desirable that new entities are automatically added when they are first referenced. For instance, in the example of “Mom’s dentist,” it could be inferred that the entity is of type “person → doctor → dentist.” Contextual inferences like this are expected, but they may be limited by the sparsity of personal data available.
Neural approaches that predict links in KGs may not be suitable for PKGs due to the lack of sufficient training data. Moreover, users should have control over the information added to their PKG and be able to verify its accuracy.
Integration with External Sources
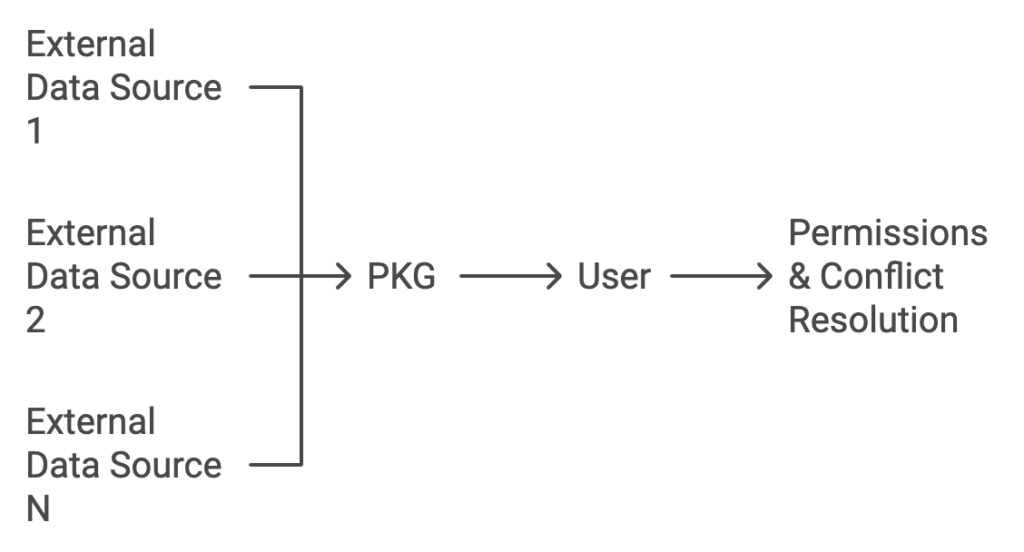
In Integration with External Sources, Personal Knowledge Graphs (PKGs) face challenges similar to those found in traditional knowledge systems but with notable differences. In conventional knowledge bases, the task of recognizing the same entity across data sources is often termed as object resolution or ontology mapping. Typically, this involves linking data between two sources, whereas in PKGs, linking must occur with multiple data repositories, creating a one-to-many challenge.
Unlike typical record linkage processes that are done once, PKG integration is a continuous process that requires ongoing synchronization. Ideally, two-way synchronization could occur, allowing updates both from and to the PKG. For instance, a user could ask an assistant to update their address across all their registered services, or updates in a friend’s location on a social media platform could be reflected in the user’s PKG.
The PKG, however, does not aim to store every fact about an entity—just those relevant to the user. Thus, the user must be involved in granting permissions for such updates. Additionally, conflicting information arising from integration might need human intervention, potentially with automatic suggestions to assist.
SEO Takeaways
There are some interesting SEO takeaways that can be applied to content creation and optimization strategies:
Contextual Relevance and Entity Relationships
PKGs focus on entities personally relevant to users, emphasizing the importance of context and individual relationships. It’s crucial to create content that is contextually relevant to the target audience. This means considering how different users may view and interact with the same entity (e.g., different products, services, or individuals).
Using schema markup to define relationships between entities on your site can help search engines understand the context, which may improve visibility in knowledge panels and direct answers.
Personalization and User-Centric Content
Personal knowledge graphs are highly personalized, representing entities that are meaningful to the user. This highlights the growing importance of personalization.
Content that addresses specific user needs, preferences, and personalized information (such as recommendations based on user behavior) can improve user experience and engagement.
Consider implementing dynamic content strategies that adapt to individual users based on their preferences, location, or past interactions with your site.
Addressing Sparse Information
PKGs often contain limited information about entities, which highlights the importance of catering content to both detailed and sparse contexts. It means balancing in-depth content with concise, easily digestible information for users who may need only specific details.
Focus on optimizing content for different user intents—provide in-depth guides for users seeking comprehensive information, while also offering quick, straightforward answers for those who need only snippets.
Entity Linking and Long-Tail Queries
PKGs face challenges related to linking entities with little information, similar to how users might use long-tail keywords or specific phrases in searches. Targeting long-tail keywords and incorporating entity-based content helps address diverse user queries, especially those with specific or niche interests. Optimize for long-tail keywords and include contextual variations (e.g., synonyms, colloquial terms) to capture a wide range of user search intents.
Dynamic Information and Updates
PKGs must be continuously updated and maintained, especially when changing user-related information. Keeping content up to date is essential, particularly for content that changes frequently, like event details, product updates, or news. Regularly review and update content to maintain relevancy and utilize structured data to signal updates to search engines.
Two-Way Integration and User Control
Integrating external data with PKGs involves importing and exporting relevant information with user control in mind. Consider ways to allow users to contribute to or personalize their experience on your site—such as user-generated content, reviews, or interactive elements that gather user input.
Use structured data to highlight user-contributed content, which can improve content relevance and authority from an SEO perspective.
Semantic Categories and Grouping
PKGs may need freely defined semantic categories to group related entities. This suggests the value of topic clustering, where content is organized into well-defined clusters that link internally.
This not only helps users navigate your content but also signals topical authority to search engines.Implement a strong internal linking strategy to connect content within the same topic cluster, helping search engines understand the scope of your expertise.
Summary
Personal Knowledge Graphs (PKGs) represent a novel approach to organizing structured information about entities that are personally relevant to individual users. Unlike traditional Knowledge Graphs, PKGs focus on entities that may not be globally significant but are important to the user’s daily life, featuring a distinctive “spiderweb” layout with the user at the center.
The paper outlines several key research challenges in developing PKGs, including knowledge representation, semantic annotation, automatic population, and integration with external sources.
While PKGs show promise for enhancing personal assistants and information systems, they face unique challenges in implementation, evaluation, and privacy protection that require further research attention.
You can access this paper by visiting: