Patent Overview
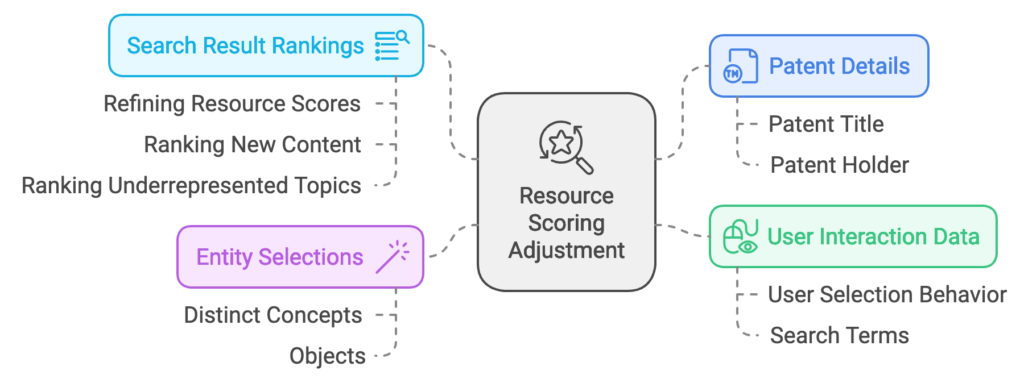
The patent, titled “Resource Scoring Adjustment Based on Entity Selections,” is held by Google. It focuses on improving search result rankings by leveraging user interaction data tied to specific entities referenced within online resources (like web pages, articles, or documents).
This is particularly relevant for content with limited user interaction data, such as new web pages or underrepresented topics. Google’s system utilizes user selection behavior, search terms, and entities (distinct concepts or objects) to refine how resources are scored and ranked in response to search queries.
Detailed Analysis of Components
Entity-based Resource Scoring
The core innovation of the patent is the shift from traditional keyword-based ranking to entity-based adjustments. Here’s a breakdown of the main components:
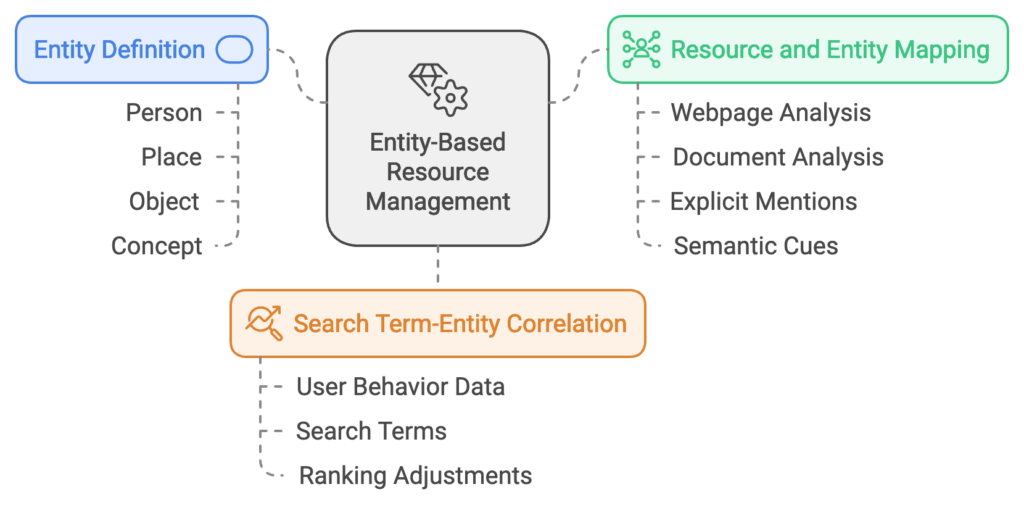
- Entity Definition: In this context, an entity is defined as a distinct, identifiable item like a person, place, object, or concept. Entities serve as the focal point for categorizing and ranking resources.
- Resource and Entity Mapping: Each webpage or document (referred to as a “resource”) is analyzed for entities it references. The patent describes a process for associating resources with entities through explicit mentions or semantic cues.
- Search Term-Entity Correlation: The system captures user behavior data associated with specific search terms. This data, tied to entities, influences ranking adjustments for search results.
By focusing on entities rather than isolated keywords, Google aims to improve the relevance of search results, recognizing that a single search term can relate to multiple entities (e.g., “Apple” as a fruit or a tech company).
The Role of User Behavior Data
User interaction data plays a critical role in this system:
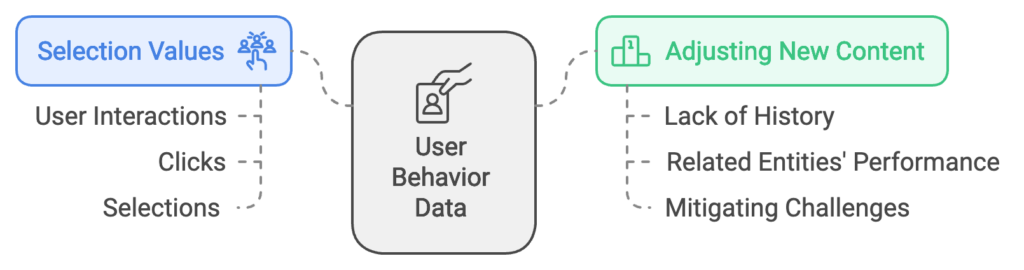
- Selection Values: Each search result interaction (clicks, selections) generates a “selection value.” This value reflects the relevance of a resource based on how frequently users select it in response to specific queries.
- Adjusting New Content: The patent emphasizes adjustments for resources lacking user behavior history, allowing newer content to be ranked based on related entities’ performance. This process mitigates the challenge of new content not having sufficient interaction data to rank accurately.
Google essentially uses user behavior as a feedback loop, where positive interactions can boost a resource’s visibility for similar queries in the future.
System Components & Process Flow
The patent describes a multi-step process to capture, evaluate, and adjust resource rankings:
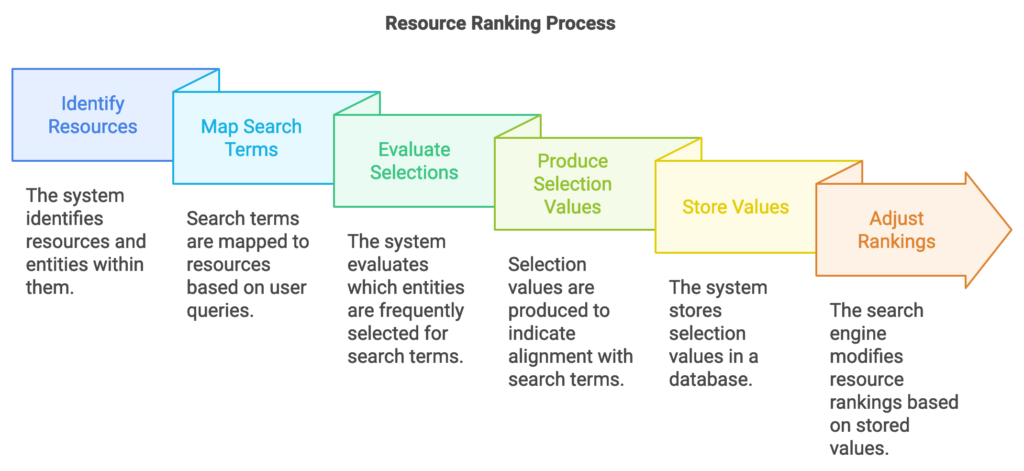
- Accessing Resource and Search Data:
- The system first identifies resources (webpages, documents) and the entities within them.
- Search terms are then mapped to these resources based on user queries, capturing how frequently users select a particular resource for specific search terms.
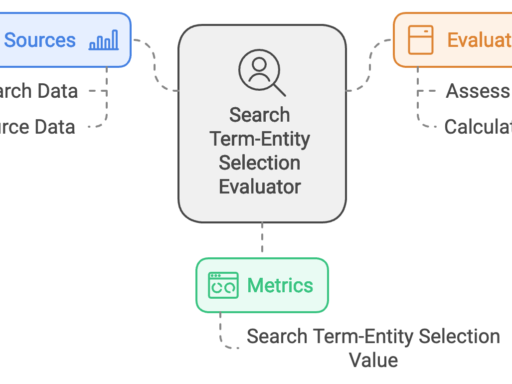
- Search Term-Entity Selection Evaluation:
- Using search and selection logs, the system evaluates which entities are frequently selected for given search terms.
- This analysis produces “search term-entity selection values,” a metric indicating how well an entity aligns with a search term based on historical user interactions.
- Ranking Adjustments:
- The system stores these selection values in a database, allowing them to influence ranking adjustments.
- The search engine can then modify a resource’s rank based on how well its associated entities have performed in similar contexts.
Resource Ranking Adjustments
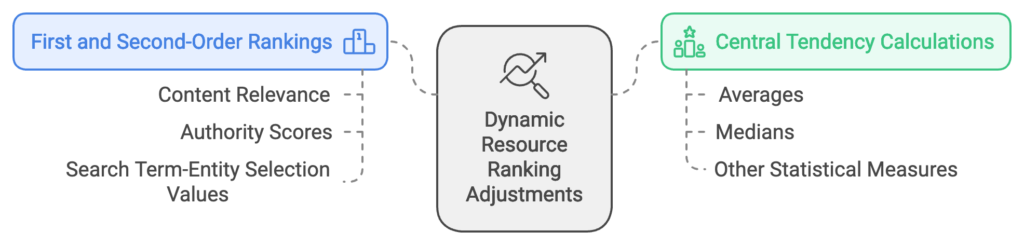
This section of the patent focuses on the methods for dynamically adjusting the ranking of search results based on selection values:
- First and Second-Order Rankings: Resources are initially ranked based on conventional factors (like content relevance and authority scores). The second order involves adjustments informed by search term-entity selection values.
- Central Tendency Calculations: When aggregating user behavior data, the system may calculate averages, medians, or other statistical measures to inform ranking changes. This allows for nuanced adjustments based on patterns in user behavior.
Technical Insights from the Patent
Resource Identification and Entity Selection
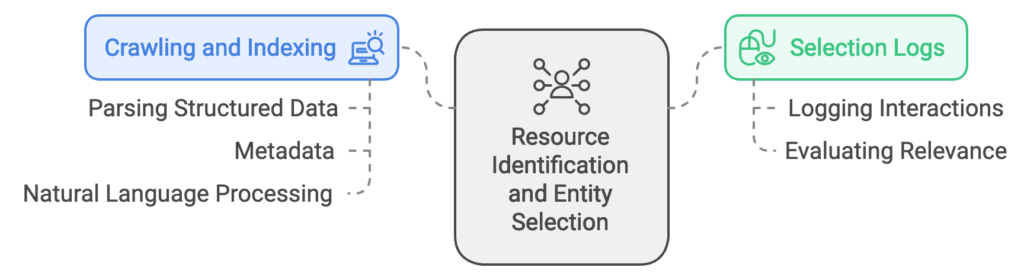
The patent’s core involves identifying entities within resources and mapping these entities to search terms through user interactions. Key processes include:
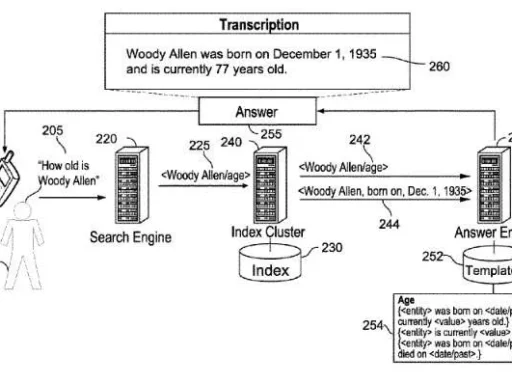
- Crawling and Indexing: The search engine crawls web resources, identifying and indexing entities associated with each page. This process may involve parsing structured data (like Schema.org markup), metadata, or natural language processing to detect and annotate entities.
- Selection Logs: User interactions with search results are logged, forming a basis for evaluating entity relevance. These logs are instrumental in determining which resources best match search terms over time.
Calculating Search Term-Entity Selection Values
The methodology to calculate the relevance of an entity for a specific search term includes:
- Selection Values: These are ratios calculated from how often a resource is selected for a given search term relative to its total impressions. A high selection value indicates strong relevance.
- Aggregating Data: The patent describes summing or averaging selection values across different resources referencing the same entity. For example, if multiple webpages referencing “Mount Fuji” consistently perform well for the term “climb Fuji,” this entity would receive a boost for related queries.

Adjusting Search Rankings
Once search term-entity selection values are established, they influence ranking adjustments:
- Weighting Mechanism: Entities within a resource are assigned weights based on prominence or content proportion. These weights are factored into the ranking adjustment process, amplifying or diminishing the influence of particular entities.
- Use of Confidence Scores: The patent mentions confidence scores, which measure the reliability of selection values based on sample size. This ensures that the ranking adjustments are statistically significant and not skewed by outliers or limited data.

Use of Confidence Scores and Weighting
The system accounts for data reliability through confidence scores, affecting how ranking adjustments are applied:
- High vs. Low Confidence Scores: If a selection value is based on a significant number of user interactions, a high confidence score will be assigned, making its impact on rankings stronger. Conversely, lower confidence scores indicate limited data reliability.
- Entity Weighting: The prominence of entities within a resource affects its influence. For example, if a resource prominently features “Fuji apples,” the entity’s weighting will be higher, boosting its ranking influence for related queries.
Importance of User Behavior
User engagement is a critical factor in this model, as it directly impacts the selection values that inform rankings:
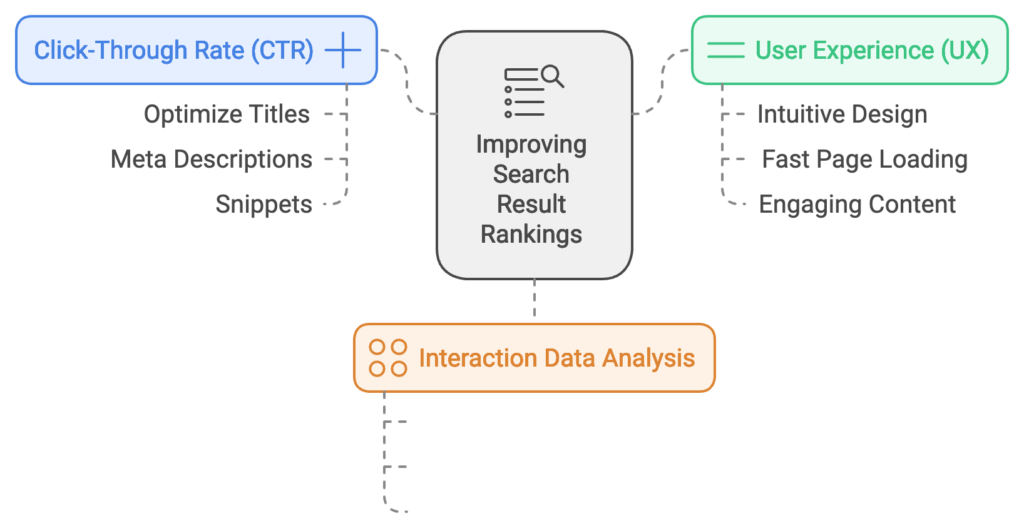
- Focus on Click-Through Rate (CTR): A high CTR for search results can increase the selection value of a resource, boosting its ranking. Optimize titles, meta descriptions, and snippets to encourage clicks.
- Improve User Experience (UX): Pages that keep users engaged contribute to positive behavioral data. Invest in intuitive design, fast page loading, and engaging content to retain users and reduce bounce rates.
- Analyze Interaction Data: Monitor metrics like CTR, bounce rates, and dwell time to gauge user satisfaction. These metrics inform Google’s selection values and, ultimately, search result rankings.
Impact on New Content
One significant aspect of the patent is its approach to handling new or underrepresented content:
- Rapid Ranking Adjustments: New content can be adjusted in rankings based on related entities’ historical performance, even without an extensive user interaction history. This underscores the importance of immediate relevance to prominent entities when launching new pages.
- Content Freshness: Frequent updates and fresh content tied to high-relevance entities may help new pages rank quickly, leveraging entity associations to bypass traditional ranking limitations.
Technical SEO Considerations
The technical depth of the patent suggests several best practices:
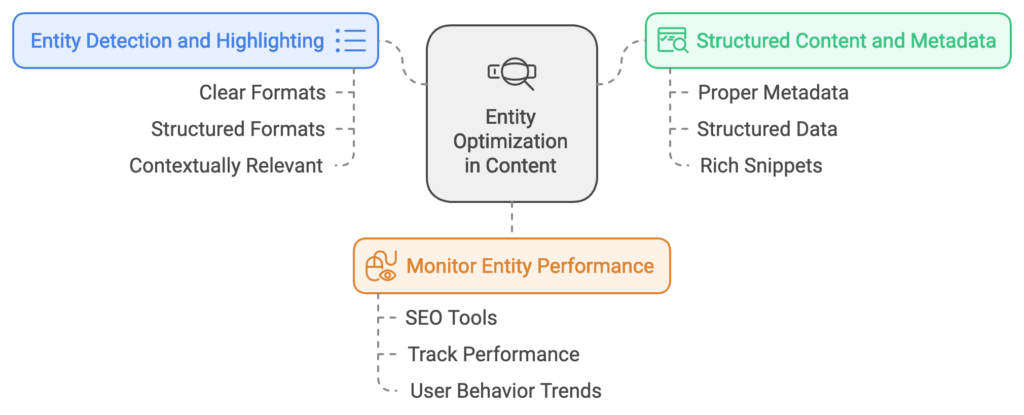
- Entity Detection and Highlighting: Use clear, structured formats (headings, lists, bullets) to highlight entities within content. Ensure that the main entities are visible and contextually relevant.
- Structured Content and Metadata: Proper metadata, including structured data and rich snippets, assists search engines in identifying relevant entities and their prominence within content. This can impact selection values tied to entities.
- Monitor Entity Performance: Use SEO tools to track how specific entities are performing in search. Understanding which entities drive traffic allows for targeted content updates that align with user behavior trends.
Weighting Mechanisms and Their Implications
One of the critical features of the patent is how entities are weighted within resources. This weighting directly affects a resource’s ability to rank for particular search terms:
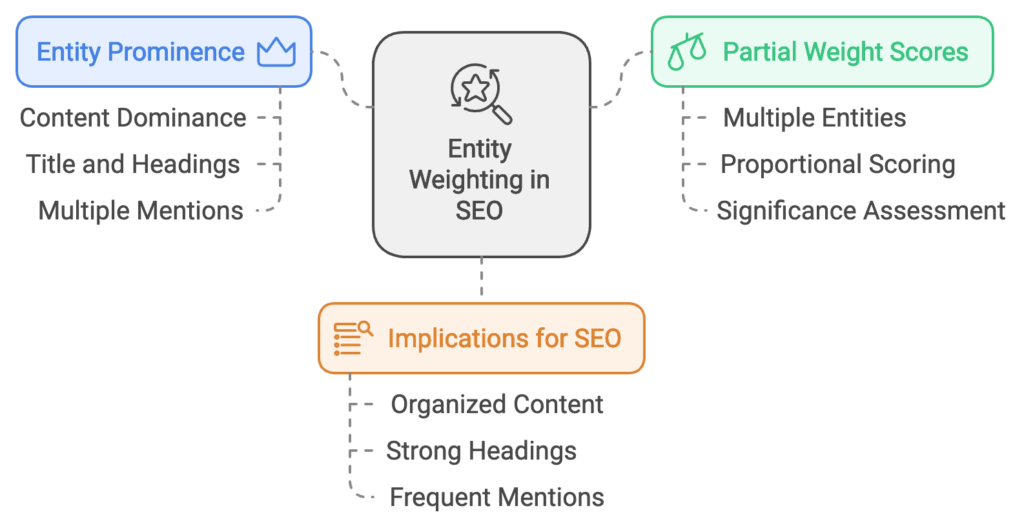
- Entity Prominence: Entities that dominate the content of a resource (e.g., appearing in the title, headings, or multiple mentions throughout the text) may receive a higher weighting. This increased weighting can amplify the influence of that entity’s selection value in the overall ranking.
- Partial Weight Scores: Resources that mention multiple entities are scored proportionally. If a page mentions “Mount Fuji” and “Fuji apples,” each entity’s significance within the content is assessed, affecting its ability to influence rankings for queries tied to those entities.
- Implication for SEO: For SEO professionals, this means content must be organized to clearly highlight the primary entities. The use of strong headings, introductory paragraphs, and frequent mentions of the main entity will help solidify its perceived importance.
Normalization and Aggregation Techniques
The patent discusses various techniques for aggregating user behavior data related to entities:
- Summation and Averaging: Selection values are often aggregated by summing user interactions across different resources referencing the same entity. The mean or median values can then be calculated to normalize the impact.
- Central Tendency: Central tendency calculations (mean, median, or mode) are employed to assess how well an entity aligns with search terms based on aggregated user behavior. These calculations help smooth out anomalies in user data, providing a more stable basis for ranking adjustments.
- Implication for SEO: Creating comprehensive content that covers the main aspects of an entity can ensure that aggregated user data skews favorably. Pages should be complete, authoritative, and provide in-depth information on the topic to capture diverse user interactions.
Use of Distributed Databases for Data Handling
The patent briefly touches on handling vast amounts of search data and user interactions. The system appears designed to manage sparse and vast datasets, likely through distributed databases:
- Handling Large Datasets: Given the extensive data required for entity-based ranking adjustments, the search system likely uses scalable data structures. These structures support vast and sparse matrices of search term-entity correlations.
- Data Reliability: By leveraging large datasets and confidence scores, the system can differentiate between reliable and unreliable data. This ensures that resources with solid user engagement are properly rewarded.
- Implication for SEO: It’s beneficial to create content that targets long-tail keywords and niche topics, as this can capture interactions in underrepresented areas. High-quality content on these topics may benefit from Google’s data aggregation process, offering potential visibility advantages for niche content.
Practical SEO Takeaways and Recommendations
The patent provides deep technical insights that can inform advanced SEO strategies. Here’s how to apply these insights practically:
Semantic Relevance Over Keyword Density
One of the key takeaways from this patent is that Google’s ranking adjustments lean heavily on semantic relevance. Here’s how to enhance semantic SEO:
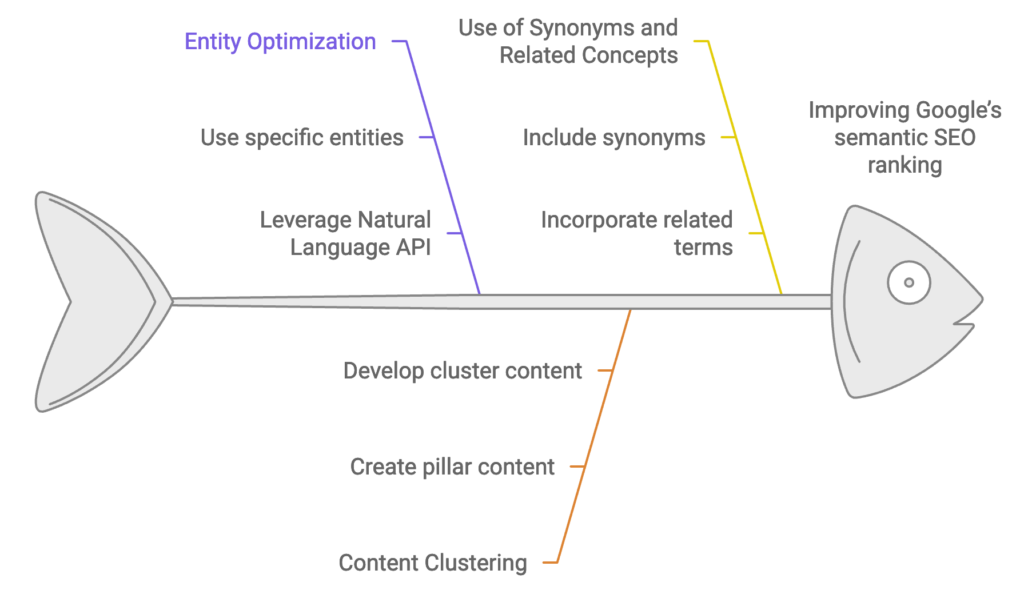
- Entity Optimization: Ensure that each piece of content centers around specific entities that are clearly related to the topic. Use tools like Google’s Natural Language API to see how your content is perceived in terms of entities and their relevance.
- Content Clustering: Use topic clustering techniques where a primary page (pillar content) focuses on a core entity, while related pages (cluster content) explore subtopics and closely related entities. This will improve semantic relevance and the authority of the main topic.
- Use of Synonyms and Related Concepts: To reinforce entity relevance, include synonyms and related terms naturally within the content. This ensures that the content captures a broader semantic field, appealing to Google’s entity-recognition algorithms.
Focus on Structured Data and Rich Snippets
Structured data is a cornerstone for entity recognition, and its correct application can significantly enhance visibility:
- Schema Markup: Implement Schema.org markup for key entities. If the content is about a person, place, product, or event, use specific schema types (e.g., Person, Place, Product, Event) to clarify the entity type to search engines.
- Breadcrumbs and Hierarchical Structuring: Use structured navigation elements like breadcrumbs to showcase content hierarchy. This helps Google understand the relationship between pages, reinforcing the topical structure.
- Rich Snippets: Optimize content for rich snippets by providing direct, concise answers to common queries within the page’s HTML (e.g., using <h2> tags for FAQs). This can increase the resource’s selection value by making it more attractive in search results.
User Engagement Metrics as a Ranking Factor
Behavioral data, particularly how users engage with search results, is pivotal. Here’s how to leverage this aspect:
- Meta Tags Optimization: Craft compelling meta titles and descriptions to improve CTR. Include strong calls to action, clear benefits, and relevant entities within the meta tags.
- UX and Mobile Optimization: A positive user experience, especially on mobile devices, can increase the likelihood of positive user interactions. Focus on mobile-first design principles, fast loading times, and intuitive navigation to encourage engagement.
- Interactive and Visual Content: Including interactive elements (like videos, infographics, and polls) can increase dwell time. This type of content often leads to better engagement metrics, influencing selection values positively.
Content Freshness and Entity Association
The patent’s emphasis on dynamically adjusting rankings, especially for newer content, highlights the importance of timely updates:
- Regular Content Updates: Refresh content regularly, especially if it’s linked to rapidly changing entities (like news topics or trends). This practice can help resources maintain relevance.
- Leverage Hot Topics: Capitalize on trending entities by creating content around them. Use tools like Google Trends or BuzzSumo to identify emerging entities that align with your industry.
- Entity Association for New Content: When publishing new content, clearly associate it with well-known entities. This association can help Google’s algorithm understand its relevance, even if the content lacks an interaction history.
Analyze and Monitor Entity Performance
Understanding which entities drive traffic and engagement is crucial for a data-driven SEO strategy:
- Entity Analysis Tools: Use SEO tools that offer entity analysis capabilities (e.g., SEMrush, Ahrefs, or Google’s own entity search tools) to identify top-performing entities in your content. This insight helps prioritize which entities to target or reinforce.
- Competitor Analysis: Examine competitor content to understand which entities they focus on and how they structure their content around those entities. This can inform your strategy to optimize for similar or related entities.
- SERP Analysis: Regularly analyze the search engine results page (SERP) for your target queries to identify which entities appear frequently. This analysis can reveal Google’s preference for certain entities, guiding content adjustments.
Focus on Local and Niche Entities
For local SEO or niche industries, targeting specific entities can differentiate content:
- Local Entities: If operating in a local market, emphasize entities tied to specific locations (like landmarks, local businesses, or community figures). This can improve visibility in local searches.
- Niche Expertise: For industries with a specialized audience, target niche entities that competitors may overlook. This can attract a dedicated audience and establish authority within that niche.
Conclusion: A Paradigm Shift in SEO Strategy
The patent reveals a significant evolution in Google’s approach to search ranking. The shift from a keyword-centric model to one that prioritizes entities, user behavior, and semantic relevance requires a new way of thinking about SEO.
The technical complexities of search term-entity selection values, confidence scores, and weighted adjustments illustrate that SEO is no longer just about keywords but about context, relevance, and user engagement.
Key Takeaways:
- Prioritize entities over individual keywords. This means focusing on semantic relevance, structured content, and clarity in representing core topics.
- User interaction data is a powerful ranking signal. Optimizing for CTR, UX, and engaging content can positively impact rankings.
- Structured data is a must. Proper implementation helps search engines understand content better, especially for complex or new entities.
- Adapt content strategies for new and niche content by aligning it with well-established entities, offering a way to bypass traditional ranking limitations for fresh content.
As Google’s algorithms continue to evolve, staying ahead in SEO will require a keen understanding of these shifts. Optimizing for entities and user engagement, focusing on structured data, and leveraging timely content updates are foundational steps toward future-proofing SEO strategies in line with Google’s innovations.