Overview
The patent, titled “Systems and Methods for Using Contrastive Pre-Training to Generate Text and Code Embeddings,” introduces a novel approach to creating more precise text and code embeddings through contrastive pre-training.
This machine learning technique allows models to distinguish between similar and dissimilar data, enhancing their performance across a variety of natural language and code-related tasks.
Key applications include text classification, code understanding, and cross-modal retrieval, collectively strengthening language models’ ability to interpret and process both text and code.
Patent Mechanics
The patent presents a system that applies contrastive pre-training to improve embeddings for tasks involving both natural language and code. Here’s a breakdown of the operational design:
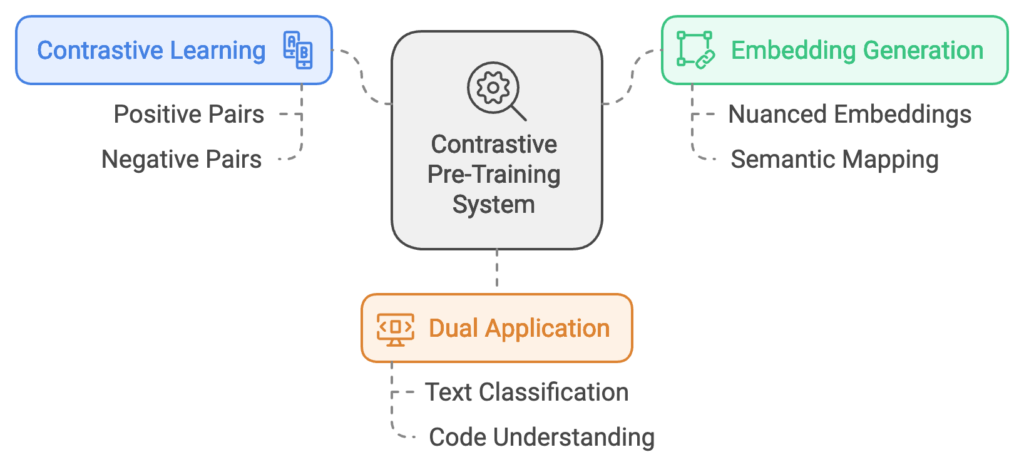
Contrastive Pre-Training: At the core of this innovation is contrastive learning, where the model learns to differentiate between pairs of similar and dissimilar data. It processes positive pairs (related data) and negative pairs (unrelated data) to fine-tune its ability to recognize and separate distinct features. For example, related code snippets or associated documentation might be fed as positive pairs, while unrelated text or code serves as negative pairs.
Embedding Generation: This system generates embeddings—vector-based representations that capture the semantics of text or code. By employing contrastive pre-training, the embeddings become more nuanced, mapping similar text or code segments closer in the embedding space and unrelated ones further apart.
Dual Application for Text and Code: Addressing both text and code data broadens the embeddings’ utility across applications, such as:
- Text Classification: Categorizing text data based on its content.
- Code Understanding: Enhancing comprehension and analysis of code.
- Cross-Modal Retrieval: Supporting retrieval tasks where the query might be in text and the result in code (or vice versa).
Training Pipeline
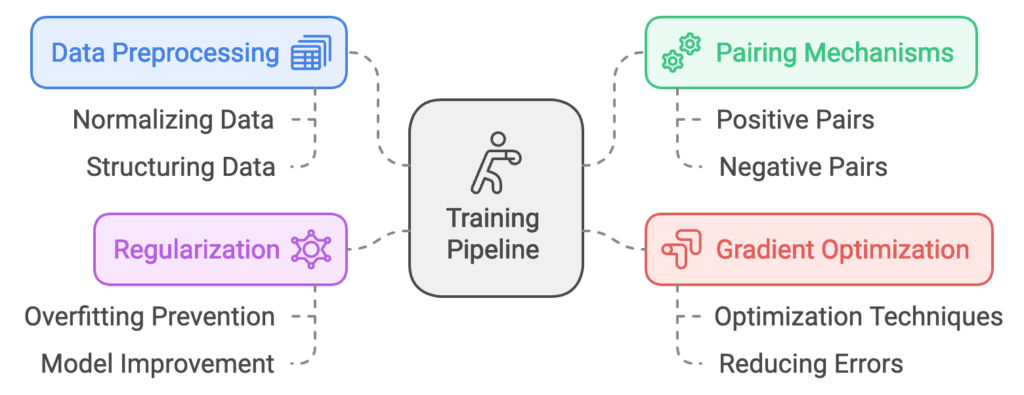
The patent also details a unique training pipeline with multiple stages aimed at maximizing embedding quality:
- Data Preprocessing: Normalizing and structuring text and code input data.
- Pairing Mechanisms: Creating positive and negative pairs to support contrastive learning.
- Gradient Optimization: Using optimization techniques to fine-tune embeddings, reducing errors in differentiating positive and negative pairs.
- Regularization: Applying methods to avoid overfitting and improve the model’s generalizability.
Optimization Techniques
To enhance performance, the system incorporates various optimization strategies:
- Loss Function Engineering: A tailored loss function ensures positive pairs are as similar as possible, while negative pairs remain distinct.
- Batch Normalization and Dropout Layers: These layers help regulate the learning process, ensuring the model doesn’t overfit to specific data but maintains broad applicability.
- Parameter Tuning: Hyperparameter adjustments help refine embedding consistency and quality across tasks.
Enhanced Retrieval Capabilities
This system significantly improves retrieval tasks where a natural language query aims to retrieve code (or vice versa). By aligning embeddings for both text and code, it supports accurate cross-modal retrieval.
SEO Insights
The technical strategies and applications outlined in this patent have direct implications for SEO, particularly for platforms and systems that use embeddings for search optimization, content discovery, and recommendation.
- Improved Semantic Understanding: The use of precise embeddings enhances search engines’ and recommendation systems’ ability to interpret user intent, leading to more relevant content rankings and improved search outcomes.
- Contextual Relevance: By identifying relevant content more accurately, the contrastive learning approach can improve SEO by ranking results based on more sophisticated, context-aware embeddings.
- Cross-Modal Search Enhancements: Embeddings optimized for both text and code support cross-modal searches (text-to-code or code-to-text), enabling more comprehensive SEO for developer platforms or content with mixed data formats.
- Personalized Content Recommendations: Improved embeddings translate to more accurate user intent capture, allowing for better content personalization and engagement—benefits that can positively impact SEO metrics like time-on-page and user interaction.
- Content Clustering and Organization: With robust text classification and clustering capabilities, these embeddings can assist in categorizing large volumes of content, improving site structure and internal linking for SEO.
- Enhanced Rich Snippets and Feature Extraction: Embedding models trained with contrastive learning can more effectively identify key content details, improving the relevance of rich snippets in search results and boosting site visibility.
- Contextual Keyword Clustering: By creating more related keyword clusters, these embeddings can support effective keyword targeting, refining SEO strategies for broader term relevance.
- Mixed Modality Content Understanding: As platforms integrate multimedia and code, these embeddings can aid in understanding and ranking diverse content formats, enhancing SEO for sites with varied types of content.
- SEO for Technical and Code-Heavy Content: The patent’s focus on code brings unique SEO advantages for code repositories, developer documentation, and technical tutorials by making these types of content more searchable and relevant in context.
- Textual and Categorical Relevance: This approach to embeddings can help categorize content accurately, supporting SEO strategies based on specific topic relevance and aiding in page organization for SEO.
Conclusion
This patent presents a forward-thinking approach to generating versatile embeddings through contrastive pre-training, effectively bridging natural language and programming code.
With its applications in text classification, cross-modal retrieval, and contextual understanding, it offers advanced insights into SEO, especially for technical platforms and multimedia content providers.
Enhanced content discoverability, precise intent matching, and robust categorization stand out as key contributions, optimizing search and recommendation systems for better user experience and improved SEO.
Systems and Methods for Using Contrastive Pre-Training to Generate Vector Representations
Inventors: David C. Orr, Daniel E. Loreto, and Michael J. P. Collins
Assignee: Google LLC
US Patent Application: US2024/0249186 A1
Published: August 7, 2024
Filed: February 1, 2023